
Friday, April 20, 2018 From rOpenSci (https://ropensci.org/blog/2018/04/20/monkeydo/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
library(tidyverse)
library(monkeylearn)
This is a story (mostly) about how I started contributing to the rOpenSci package monkeylearn. I can’t promise any life flipturning upside down, but there will be a small discussion about git best practices which is almost as good 🤓. The tl;dr here is nothing novel but is something I wish I’d experienced firsthand sooner. That is, that tinkering with and improving on the code others have written is more rewarding for you and more valuable to others when you contribute it back to the original source.
We all write code all the time to graft aditional features onto existing tools or reshape output into forms that fit better in our particular pipelines. Chances are, these are improvements our fellow package users could take advantage of. Plus, if they’re integrated into the package source code, then we no longer need our own wrappers and reshapers and speeder-uppers. That means less code and fewer chances of bugs all around 🙌. So, tinkering with and improving on the code others have written is more rewarding for you and more valuable to others when you contribute it back to the original source.
🔗 Some Backstory
My first brush with the monkeylearn package was at work one day when I was looking around for an easy way to classify groups of texts using R. I made the very clever first move of Googling “easy way to classify groups of texts using R” and thanks to the magic of what I suppose used to be PageRank I landed upon a GitHub README for a package called monkeylearn.
A quick install.packages("monkeylearn") and creation of an API key later it started looking like this package would fit my use case. I loved that it sported only two functions, monkeylearn_classify() and monkeylearn_extract(), which did exactly what they said on the tin. They accept a vector of texts and return a dataframe of classifications or keyword extractions, respectively.
For a bit of background, the monkeylearn package hooks into the MonkeyLearn API, which uses natural language processing techniques to take a text input and hands back a vector of outputs (keyword extractions or classifications) along with metadata such as their confidence in relevance of the classification. There are a set of built-in “modules” (e.g., retail classifier, profanity extractor) but users can also create their own “custom” modules1 by supplying their own labeled training data.
The monkeylearn R package serves as a friendly interface to that API, allowing users to process data using the built-in modules (it doesn’t yet support creating and training of custom modules). In the rOpenSci tradition it’s peer-reviewed and was contributed via the onboarding process.
I began using the package to attach classifications to around 70,000 texts. I soon discovered a major stumbling block: I could not send texts to the MonkeyLearn API in batches. This wasn’t because the monkeylearn_classify() and monkeylearn_extract() functions themselves didn’t accept multiple inputs. Instead, it was because they didn’t explicitly relate inputs to outputs. This became a problem because inputs and outputs are not 1:1; if I send a vector of three texts for classification, my output dataframe might be 10 rows long. However, there was no user-friendly way to know for sure2 whether the first two or the first four output rows, for example, belonged to the first input text.
Here’s an example of what I mean.
texts <- c(
"It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.",
"When Mr. Bilbo Baggins of Bag End announced that he would shortly be celebrating his eleventy-first birthday with a party of special magnificence, there was much talk and excitement in Hobbiton.",
"I'm not an ambiturner. I can't turn left.")
(texts_out <- monkeylearn_classify(texts, verbose = FALSE))
## # A tibble: 11 x 4
## category_id probability label text_md5
## <int> <dbl> <chr> <chr>
## 1 18314767 0.0620 Books af55421029d7236ca6ecbb281…
## 2 18314954 0.0470 Mystery & Suspense af55421029d7236ca6ecbb281…
## 3 18314957 0.102 Police Procedural af55421029d7236ca6ecbb281…
## 4 18313210 0.0820 Party & Occasions 602f1ab2654b88f5c7f5c90e4…
## 5 18313231 0.176 "Party Supplies " 602f1ab2654b88f5c7f5c90e4…
## 6 18313235 0.134 Party Decorations 602f1ab2654b88f5c7f5c90e4…
## 7 18313236 0.406 Decorations 602f1ab2654b88f5c7f5c90e4…
## 8 18314767 0.0630 Books bdb9881250321ce8abecacd4d…
## 9 18314870 0.0460 Literature & Fiction bdb9881250321ce8abecacd4d…
## 10 18314876 0.0400 Mystery & Suspense bdb9881250321ce8abecacd4d…
## 11 18314878 0.289 Suspense bdb9881250321ce8abecacd4d…
So we can see we’ve now got classifications for the texts we fed in as input. The MD5 hash can be used to disambiguate which outputs correspond to which inputs in some cases (see Maëlle’s fantastic Guardian Experience post!). This works great if you either don’t care about classifying your inputs independently of one another or you know that your inputs will never contain empty strings or other values that won’t be sent to the API. In my case, though, my inputs were independent of one another and also could not be counted on to be well-formed. I determined that each had to be classified separately so that I could guarantee a 1:1 match between input and output.
🔗 Initial Workaround
My first approach to this problem was to simply treat each text as a separate call. I wrapped monkeylearn_classify() in a function that would send a vector of texts and return a dataframe relating the input in one column to the output in the others. Here is a simplified version of it, sans the error handling and other bells and whistles:
initial_workaround <- function(df, col, verbose = FALSE) {
quo_col <- enquo(col)
out <- df %>%
mutate(
tags = NA_character_
)
for (i in 1:nrow(df)) {
this_text <- df %>%
select(!!quo_col) %>%
slice(i) %>% as_vector()
this_classification <-
monkeylearn_classify(this_text, verbose = verbose) %>%
select(-text_md5) %>% list()
out[i, ]$tags <- this_classification
}
return(out)
}
Since initial_workaround() takes a dataframe as input rather than a vector, let’s turn our sample into a tibble before feeding it in.
texts_df <- tibble(texts)
And now we’ll run the workaround:
initial_out <- initial_workaround(texts_df, texts)
initial_out
## # A tibble: 3 x 2
## texts tags
## <chr> <list>
## 1 It is a truth universally acknowledged, that a single man in p… <tibble…
## 2 When Mr. Bilbo Baggins of Bag End announced that he would shor… <tibble…
## 3 I'm not an ambiturner. I can't turn left. <tibble…
We see that this retains the 1:1 relationship between input and output, but still allows the output list-col to be unnested.
(initial_out %>% unnest())
## # A tibble: 11 x 4
## texts category_id probability label
## <chr> <int> <dbl> <chr>
## 1 It is a truth universally acknowledged… 18314767 0.0620 Books
## 2 It is a truth universally acknowledged… 18314954 0.0470 Myster…
## 3 It is a truth universally acknowledged… 18314957 0.102 Police…
## 4 When Mr. Bilbo Baggins of Bag End anno… 18313210 0.0820 Party …
## 5 When Mr. Bilbo Baggins of Bag End anno… 18313231 0.176 "Party…
## 6 When Mr. Bilbo Baggins of Bag End anno… 18313235 0.134 Party …
## 7 When Mr. Bilbo Baggins of Bag End anno… 18313236 0.406 Decora…
## 8 I'm not an ambiturner. I can't turn le… 18314767 0.0630 Books
## 9 I'm not an ambiturner. I can't turn le… 18314870 0.0460 Litera…
## 10 I'm not an ambiturner. I can't turn le… 18314876 0.0400 Myster…
## 11 I'm not an ambiturner. I can't turn le… 18314878 0.289 Suspen…
But, the catch: this approach was quite slow. The real bottleneck here isn’t the for loop; it’s that this requires a round trip to the MonkeyLearn API for each individual text. For just these three meager texts, let’s see how long initial_workaround() takes to finish.
(benchmark <- system.time(initial_workaround(texts_df, texts)))
## user system elapsed
## 0.036 0.001 15.609
It was clear that if classifying 3 inputs was going to take 15.6 seconds, even classifying my relatively small data was going to take a looong time, like on the order of 4 days, just for the first batch of data 🙈. I updated the function to write each row out to an RDS file after it was classified inside the loop (with an addition along the lines of write_rds(out[i, ], glue::glue("some_directory/{i}.rds"))) so that I wouldn’t have to rely on the function successfully finishing execution in one run. Still, I didn’t like my options.
This classification job was intended to be run every night, and with an unknown amount of input text data coming in every day, I didn’t want it to run for more than 24 hours one day and either a) prevent the next night’s job from running or b) necessitate spinning up a second server to handle the next night’s data.
🔗 Diving In
Now that I’m starting to think

I’m just about at the point where I have to start making myself useful.
I’d seen in the package docs and on the MonkeyLearn FAQ that batching up to 200 texts was possible2. So, I decide to first look into the mechanics of how text batching is done in the monkeylearn package.
Was the MonkeyLearn API returning JSON that didn’t relate each input individual and output? I sort of doubted it. You’d think that an API that was sent a JSON “array” of inputs would send back a hierarchical array to match. My hunch was that either the package was concatenating the input before shooting it off to the API (which would save user on API queries) or rowbinding the output after it was returned. (The rowbinding itself would be fine if each input could somehow be related to its one or many outputs.)
So I fork the package repo and set about rummaging through the source code. Blissfully, everything is nicely commented and the code was quite readable.
I step through monkeylearn_classify() in the debugger and narrow in on a call to what looks like a utility function: monkeylearn_parse(). I find it in utils.R.
The lines in monkeylearn_parse() that matter for our purposes are:
text <- httr::content(output, as = "text",
encoding = "UTF-8")
temp <- jsonlite::fromJSON(text)
if(length(temp$result[[1]]) != 0){
results <- do.call("rbind", temp$result)
results$text_md5 <- unlist(mapply(rep, vapply(X=request_text,
FUN=digest::digest,
FUN.VALUE=character(1),
USE.NAMES=FALSE,
algo = "md5"),
unlist(vapply(temp$result, nrow,
FUN.VALUE = 0)),
SIMPLIFY = FALSE))
}
So this is where the rowbinding happens – after the fromJSON() call! 🎉
This is good news because it means that the MonkeyLearn API is sending differentiated outputs back in a nested JSON object. The package converts this to a list with fromJSON() and only then is the rbinding applied. That’s why the text_md5 hash is generated during this step: to be able to group outputs that all correspond to a single input (same hash means same input).
I set about copy-pasting monkeylearn_parse() and did a bit of surgery on it, emerging with monkeylearn_parse_each(). monkeylearn_parse_each() skips the rbinding and retains the list structure of each output, which means that its output can be turned into a nested tibble with each row corresponding to one input. That nested tibble can then be related to each corresponding element of the input vector. All that remained was to use create a new enclosing analog to monkeylearn_classify() that could use monkeylearn_parse_each().
🔗 Thinking PR thoughts
At this point, I thought that such a function might be useful to some other people using the package so I started building it with an eye toward making a pull request.
Since I’d found it useful to be able to pass in an input dataframe in initial_workaround(), I figured I’d retain that feature of the function. I wanted users to still be able to pass in a bare column name but the package seemed to be light on tidyverse functions unless there was no alternative, so I un-tidyeval’d the function (using deparse(substitute()) instead of a quosure) and gave it the imaginative name…monkeylearn_classify_df(). The rest of the original code was so airtight I didn’t have to change much more to get it working.
A nice side effect of my plumbing through the guts of the package was that I caught a couple minor bugs (things like the remnants of a for loop remaining in what had been revamped into a while loop) and noticed where there could be some quick wins for improving the package.
After a few more checks I wrote up the description for the pull request which outlined the issue and the solution (though I probably should have first opened an issue, waited for a response, and then submitted a PR referencing the issue as Mara Averick suggests in her excellent guide to contributing to the tidyverse).
I checked the list of package contributors to see if I knew anyone. Far and away the main contributor was Maëlle Salmon! I’d heard of her through the magic of #rstats Twitter and the R-Ladies Global Slack. A minute or two after submitting it I headed over to Slack to give her a heads up that a PR would be heading her way.
In what I would come to know as her usual cheerful, perpetually-on-top-of-it form, Maëlle had already seen it and liked the idea for the new function.
🔗 Continuing Work
To make a short story shorter, Maëlle asked me if I’d like to create the extractor counterpart to monkeylearn_classify_df() and become an author on the package with push access to the repo. I said yes, of course, and so we began to strategize over Slack about tradeoffs like which package dependencies we were okay with taking on, whether to go the tidyeval or base route, what the best naming conventions for the new functions should be, etc.
On the naming front, we decided to gracefully deprecate monkeylearn_classify() and monkeylearn_extract() as the newer functions could cover all of the functionality that the older ones did. I don’t know much about cache invalidation, but the naming problem was hard as usual. We settled on naming their counterparts monkey_classify() (which replaced the original monkeylearn_classify_df()) and monkey_extract().
🔗 gitflow
Early on in the process we started talking git conventions. Rather than both work off a development branch, I floated a structure that we typically follow at my company, where each ticket (or in this case, GitHub Issue) becomes its own branch off of dev. For instance, issue #33 becomes branch T33 (T for ticket). Each of these feature branches come off of dev (unless they’re hotfixes) and are merged back into dev and deleted when they pass all the necessary checks. This approach, I am told, stems from the “gitflow” philosophy which, as far as I understand it, is one of many ways to structure a git workflow that mostly doesn’t end in tears.
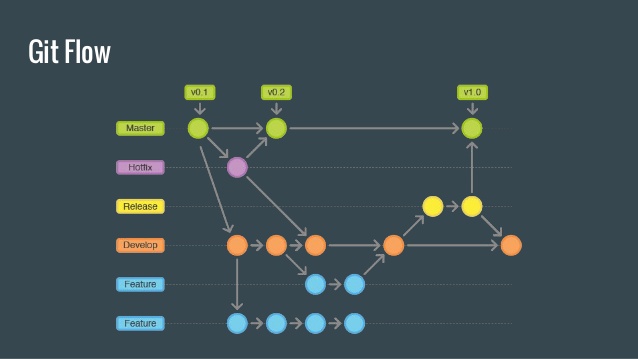
Like most git strategies, the idea here is to make pull requests as bite-sized as possible; in this case, a PR can only be as big as the issue it’s named from. An added benefit for me, at least, is that this keeps me from wandering off into other parts of the code without first documenting the point in a separate issue, and then creating a branch. At most one person is assigned to each ticket/issue, which minimizes merge conflicts. You also leave a nice paper trail because the branch name directly references the issue front and center in its title. This means you don’t have to explicitly name the issue in the commit or rely on GitHub’s (albeit awesome) keyword branch closing system3.
Finally, since the system is so tied to issues themselves, it encourages very frequent communication between collaborators. Since the issue must necessarily be made before the branch and the accompanying changes to the code, the other contributors have a chance to weigh in on the issue or the approach suggested in its comments before any code is written. In our case, it’s certainly made frequent communication the path of least resistance.
While this branch and PR-naming convention isn’t particular to gitflow (to my knowledge), it did spark a short conversation on Twitter that I think is useful to have:
Thomas Lin Pedersen makes a good point on the topic:
I prefer named PRs as it gives a quick overview over opened PRs. While cross referencing with open issues is possible it is very tedious when you try to get an overview— Thomas Lin Pedersen. March 6, 2018
This insight got me thinking that the best approach might be to explicitly name the issue number and give a description in the branch name, like a slug of sorts. I started using a branch syntax like T31-fix-bug-i-just-created which has worked out well for Maëlle and me thus far, making the history a bit more readable.
🔗 Main Improvements
As I mentioned, the package was so good to begin with it was difficult to find ways to improve it. Most of the subsequent work I did on monkeylearn was to improve the new monkey_ functions.
The original monkeylearn_ functions discarded inputs such as empty strings that could not be sent to the API. We now retain those empty inputs and return NAs in the response columns for that row. This means that the output is always of the same dimensions as the input. We return an unnested dataframe by default, as the original functions did, but allow the output to be nested if the unnest flag is set to FALSE.
The functions also got more informative messages about which batches are currently being processed and which texts those batches corresponded to.
text_w_empties <- c(
"It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.",
"When Mr. Bilbo Baggins of Bag End announced that he would shortly be celebrating his eleventy-first birthday with a party of special magnificence, there was much talk and excitement in Hobbiton.",
"",
"I'm not an ambiturner. I can't turn left.",
" ")
(empties_out <- monkey_classify(text_w_empties, classifier_id = "cl_5icAVzKR", texts_per_req = 2, unnest = TRUE))
## The following indices were empty strings and could not be sent to the API: 3, 5. They will still be included in the output.
## Processing batch 1 of 2 batches: texts 1 to 2
## Processing batch 2 of 2 batches: texts 2 to 3
## # A tibble: 8 x 4
## req category_id probability label
## <chr> <int> <dbl> <chr>
## 1 It is a truth universally acknowledged,… 64708 0.289 Society
## 2 It is a truth universally acknowledged,… 64711 0.490 Relati…
## 3 When Mr. Bilbo Baggins of Bag End annou… 64708 0.348 Society
## 4 When Mr. Bilbo Baggins of Bag End annou… 64713 0.724 Specia…
## 5 "" NA NA <NA>
## 6 I'm not an ambiturner. I can't turn lef… 64708 0.125 Society
## 7 I'm not an ambiturner. I can't turn lef… 64710 0.377 Parent…
## 8 " " NA NA <NA>
So even though the empty string inputs like the 3rd and 5th, aren’t sent to the API, we can see they’re still included in the output dataframe and assigned the same column names as all of the other outputs. That means that even if unnest is set to FALSE, the output can still be unnested with tidyr::unnest() after the fact.
If a dataframe is supplied, there is now a .keep_all option which allows for all columns of the input to be retained, not just the column that contains the text to be classified. This makes the monkey_ functions work even more like a mutate(); rather than returning an object that has to be joined on the original input, we do that association for the user.
sw <- dplyr::starwars %>%
dplyr::select(name, height) %>%
dplyr::sample_n(length(text_w_empties))
df <- tibble::tibble(text = text_w_empties) %>%
dplyr::bind_cols(sw)
df %>% monkey_classify(text, classifier_id = "cl_5icAVzKR", unnest = FALSE, .keep_all = TRUE, verbose = FALSE)
## # A tibble: 5 x 4
## name height text res
## <chr> <int> <chr> <list>
## 1 Ackbar 180 It is a truth universally acknowledged, t… <data.…
## 2 Luke Skywalker 172 When Mr. Bilbo Baggins of Bag End announc… <data.…
## 3 Shmi Skywalker 163 "" <data.…
## 4 Shaak Ti 178 I'm not an ambiturner. I can't turn left. <data.…
## 5 Lama Su 229 " " <data.…
We see that the input column, text is sandwiched between the other columns of the original dataframe (the Starwars ones) and the output column res.
The hope is that all of this serves to improve the data safety and user experience of the package.
🔗 Developing functions in tandem
Something I’ve been thinking about while working on the twin functions monkey_extract() and monkey_classify() is what the best practice is for developing very similar functions in sync with one another. These two functions are different enough to have different default values (for example, monkey_extract() has a default extractor_id while monkey_classify() has a default classifier_id) but are so similar in other regards as to be sort of embarrassingly parallel.
What I’ve been turning over in my head is the question of how in sync these functions should be during development. As soon as you make a change to one function, should you immediately make the same change to the other? Or is it instead better to work on one function at a time, and, at some checkpoints then batch these changes over to the other function in a big copy-paste job? I’ve been tending toward the latter but it’s seemed a little dangerous to me.
Since there are only two functions to worry about here, creating a function factory to handle them seemed like overkill, but might technically be the best practice. I’d love to hear people’s thoughts on how they go about navigating this facet of package development.
🔗 Last Thoughts
My work on the monkeylearn package so far has been rewarding to say the least. It’s inspired me to be not just a consumer but more of an active contributor to open source. Some wise words from Maëlle on this front:
You too can become a contributor to an rOpenSci package! Have a look at the issues tracker of your favorite rOpenSci package(s) e.g. rgbif. First ask in a new or existing issue whether your contribution would be welcome, plan a bit with the maintainer, and then have fun! We’d be happy to have you.
Maëlle’s been a fantastic mentor, providing guidance in at least four languages – English, French, R, and emoji, despite the time difference and 👶(!). When it comes to monkeylearn, the hope is to keep improving the core package features, add some more niceties, and look into building out an R-centric way for users to create and train their own custom modules on MonkeyLearn.
On y va!

Custom, to a point. As of this writing, two types of classifier models you can create use either Naive Bayes or Support Vector Machines, though you can specify other parameters such as
use_stemmerandstrip_stopwords. Custom extractor modules are coming soon. ↩︎That MD5 hash almost provided the solution; each row of the output gets a hash that corresponds to a single input row, so it seemed like the hash was meant to be used to be able to map inputs to outputs. Provided that I knew that all of my inputs were non-empty strings, which are filtered out before they can be sent to the API, and could be classified I could have nested the output based on its MD5 sum and mapped the indices of the inputs and the outputs 1:1. The trouble was that I knew that my input data would be changing and I wasn’t convinced that all of my inputs would be receive well-formed responses from the API. If some of the text couldn’t receive a corresponding set of classification, such a nested output would have fewer rows than the input vector’s length. There would be no way to tell which input corresponded to which nested output. ↩︎ ↩︎
Keywords in commits don’t automatically close issues until they’re merged into master, and since we were working off of dev for quite a long time, if we relied on keywords to automatically close issues our Open iIsues list wouldn’t accurately reflect the issues that we actually still had to address. Would be cool for GitHub to allow flags like maybe “fixes #33 –dev” could close issue #33 when the PR with that phrase in the commit was merged into dev. ↩︎
Filed under
Suggest an edit
Open a pull request
