
Friday, June 8, 2018 From rOpenSci (https://ropensci.org/blog/2018/06/08/rprofile-julia-silge/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
In this occasional series, we interview someone using a loosely defined set of interview questions for the purpose of demystifying the creative and development processes of R community members. This interview was conducted and prepared by Kelly O’Briant as part of an rOpenSci project called rOpenInterviews.

Dr. Julia Silge [@juliasilge on Twitter] is a data scientist at Stack Overflow. We talked about why R brings Julia joy, her path to a career in data science and what it was like to co-write a book for O’Reilly Media. This interview occurred on February 3, 2018 at the RStudio Conference in San Diego.
KO: What is your name, job title, and how long have you been using R?
JS: My name is Julia Silge and I’m a data scientist at Stack Overflow. I have been working in R for less than three years.
KO: Wow! What were you all about before that?
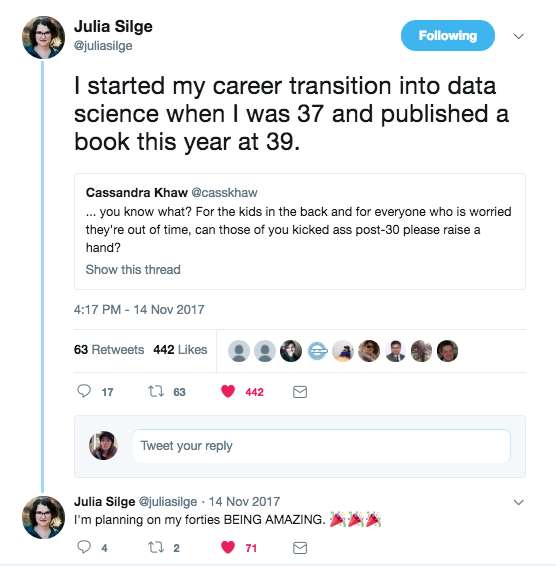
JS: I know a lot of people in data science say, “oh I had this weird path that brought me to where I am today.” But I actually do think I have an especially weird and unusual path that included things like being laid off from an ed tech startup, and being a stay at home mom for several years. But if I look back, rather than literally telling you all the steps that got me here, I would say one big piece of what brought me to the role that I have today is my formal education.
I have a bachelor’s degree in physics, a PhD in astrophysics, and I did a postdoc and research for a while. All of this education involved a lot of intense quantitative background, a lot of mathematical training, a lot of hands-on involvement with data. I was responsible for analyzing real world data generated by physical processes, writing code, making plots, writing prose to explain it - these things are all a big part of my professional identity.
Another big piece is that I’ve been involved in education at a high level for a long time. I taught as a professor for a number of years. I taught mostly physics and some astronomy at a couple of smaller universities. Later on I worked at an ed tech startup doing content development, so sort of working in education from a slightly different angle.
KO: What level were you targeting?
JS: I worked on a product for higher ed STEM course content. The part of my career that has focused on, “how do people learn and understand this science and technology space?” really informs how I do data science. A huge part of what I do in a data science organization is communicate with people about what things mean. The fact that I analyzed some data or I trained some model is great, but if I can’t explain to stakeholders what it means, then we can’t use it to make business decisions.
The part of my career that has focused on, “how do people learn and understand this science and technology space?” really informs how I do data science.
KO: What have the last three years working in R meant to you? Why is that a big deal for you?
JS: I learned my first programming language back in high school - Basic. But my first serious programming language was learning C in college and in grad school. When I got to a point in my professional life where I was interested in making a transition into data science, I sat back and I surveyed the programming language landscape. I said, okay, I need to learn something new here and update these skills so that maybe someone will hire me to do something. And I dabbled a little bit in - what are the kids doing these days? What are they using?
KO: What’s the hot new thing?
JS: Yeah! I dabbled in Python and in R, and I think there are two reasons why R clicked for me. The first was discovering the tidyverse tooling for handling data. The “data first” functional APIs of the tidyverse, the ease with which one can manipulate and visualize data, also the functional programming flavor of being able to handle data with things like purrr, that was an immediate click for me. Given the kind of programming background I came from, that was an immediate joy and delight. Object oriented programming was kind of the opposite experience. I was like, oh programming in this idiom is NOT bringing me delight. It’s not a value judgement I’m making; it’s just what happened to me.
KO: Some things bring you delight, some things do not!
JS: Exactly, so that was the first big piece - when I experimented with R, the joy was there. The second thing was that when I was mentally gearing up to enter a highly technical field again. I was literally thinking, alright, time to get back in there, it’s going to be rough, but I can do it. And my experience with entering the R community was in fact almost entirely the opposite.
I was literally thinking, alright, time to get back in there, it’s going to be rough, but I can do it.
The R open source community turned out to be exactly opposite of what my expectations were. It was welcoming, vibrant and there were lots of different kinds of voices doing lots of different kinds of things. There were a few individuals who were willing to invest in me, share their platform and partner with me in some significant ways that opened huge doors. It all happened fairly early, and so this made the R open source community feel like - like this is what I want to center my professional identity around because this is the way it is.
KO: Can you talk a little bit about how you found and started working with these mentors who were willing to invest time in you and how that came to be?
JS: I started learning on my own. I’m geographically somewhat isolated because I do not live in really a big tech hub. But I spent about six months taking every single MOOC that exists. In the process of doing this, one of my goals was to develop a portfolio. I pictured myself applying for jobs, and I wanted this portfolio to be something that would demonstrate that yes, I’m worth considering for this job. So that’s when I started blogging. I have been astonished to see that the blog has had a much richer impact on my professional life.
The first iteration was a Jekyll blog. I was trying to figure out how to write in Rmarkdown and I found Dave Robinson’s script that he used to do it. When I published my first blog post, I mentioned him on twitter like, “hey thanks for doing this!” He retweeted my blog post, and then Hadley Wickham saw it and Hadley retweeted it. This was my first blog post ever! My phone was exploding with notifications. I was like, what is going on!? This is amazing!
That year I went to rOpenSci’s unconference; this was in 2016. It was the first time I had met anyone in the R community at all. I remember getting a twitter DM from Karthik Ram and he said, “Hey you don’t know me, but we have this unconference…” And I was like, gosh I don’t know these strangers from the internet! But I guess it’s the way to go. That’s what you do now, you go and you meet strangers from the internet.
When I showed up at unconference the first day, Dave Robinson was also there. We were deciding what issues to work on, and people were putting ideas on post-it notes. Dave turned to me and said, “Hey, do you want to build a package for text mining?” And I said, “Yes! That sounds amazing! I would love to do that.” And so we sat down and started working on it.
KO: That’s a great origin story!
JS: Yes! That is the origin story of tidytext! We started working on it at unconf in 2016 and by the time we left unconf, we had the main function, sentiment lexicons, and it was passing on Travis. It was on CRAN maybe 3 months later. The book was published maybe a year after that.
KO: Yeah, I remember I was at the NYR conference when I met you for the first time and Dave was going off into another room to finish edits for a deadline. Jared [Lander] was making fun of him for doing 17 things at once. Do you want to talk at all about the process of writing a book for O’Reilly and how that got done?
JS: That was amazing. It’s the largest single body of work I’ve done since my PhD dissertation. It was really rewarding, and great to work with a generous and knowledgeable partner like Dave. It was exciting to see this project get out into the world. I love physics and astronomy, but I think if I were 15 years younger than I am, I would be doing something like computational linguistics. It was not a very active area of research when I was deciding what to major in. I really do love the intersection of language and math, and how to model those things.
I describe the process of how the book came to be as an organic growing. I was actively blogging about how to use the new package we’d made. Both Dave and I place a really high value on excellent documentation. For us, that looks like multiple vignettes, so we started adding more vignettes to tidytext. Then we were blogging, and we got to the point where we were generating quite a bit of focused material. The timing was great because bookdown was just starting to get out into the community. We thought, this would not be that hard; let’s set up a bookdown project.
The plan was to make half the book about concepts and functions, how to implement text mining using these tidy principles, and half to be case studies, end-to-end demonstrations of how you can apply those principles. So we made the plan and divided up the work by alternating primary author for each of the chapters. It started with disparate material and organically grew into a book.
KO: I’ve never found a person who I could write effectively with. Being able to connect on that level, to ultimately create something that comes together without sounding very disjointed, is incredibly impressive.
JS: We have really similar perspectives and voice on a lot of things. We have a deep disagreement when it comes to the number of spaces a tab should have. One of us thinks that there should be four spaces in a tab, and one of us is wrong.
KO: Now that you’ve been in industry for a while, do you miss academia? Do you miss teaching?
JS: I feel like I still get opportunities to do the things I liked about teaching. I enjoy speaking at conferences. Internally at Stack Overflow, on every other Friday afternoon we have an internal R session for software developers who are interested in developing data skills. We hang out for an hour or an hour and half. These are very skilled people so I don’t want to sound like - and then I teach them things! It’s more like we go through a tutorial, we practice using real Stack Overflow data to ask a real question we don’t know the answer to, and then I demonstrate how to use R. So that’s another way I get to exercise those academic skills a little bit.
I absolutely went through a grieving period when I left academia. Even in the midst of that, I was sure it was right for me to leave. I was mourning, but I was confident in my decision to leave. If I ever miss something about academia, I will always stop and remember, I am missing the idea of what I wish academia was. I’m not missing the way it actually was to be in academia.
KO: I can relate to that 100%. Thank you for sharing all this Julia, I really enjoyed chatting with you.
This interview occurred at the 2018 RStudio Conference. Special thanks to Julia Silge for participating in the project!
Filed under
Suggest an edit
Open a pull request
