
Thursday, December 20, 2018 From rOpenSci (https://ropensci.org/blog/2018/12/20/spelling-20/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
We have released updates for the rOpenSci text analysis tools. This technote will highlight some of the major improvements in the spelling package and also the underlying hunspell package, which provides the spelling engine for the spelling package.
install.packages("spelling")
Update to the latest versions to use these cool new features!
🔗 Automatic Checking of README and NEWS files
Users that are already using spelling on their packages might discover a few new typos! The new version of spelling now also checks the readme.md and news.md and index.md files in your package root directory.
spelling::spell_check_package()
# WORD FOUND IN
# AppVeyor README.md:5
# CMD description:3
# README.md:12
# devtools README.md:93
# hunspell spell_check_files.Rd:18,32
# spell_check_package.Rd:24
# README.md:31
Of course it also still checks your manual pages, vignettes and description fields. Hence we now spell check all content that is used to generate your package website with pkgdown.
🔗 Improved Markdown Parsing
Parsing of markdown files in spell_check_files() and spell_check_package() has been tweaked in a few places, resulting in less false positives.
First of all, it now properly parses the yaml front-matter and only runs the spell check only on the title, subtitle and description fields. The other fields usually contain code or options, not actual language we want to check.
spelling::spell_check_files("README.md")
# WORD FOUND IN
# AppVeyor README.md:5
# CMD README.md:12
# devtools README.md:93
# hunspell README.md:31
# readme README.md:37
# RStudio README.md:8,93
# wordlist README.md:12
Also the parser now filters words that contain @ symbol. Such a word is usually a rmarkdown citation or twitter handle, or email address, neither of which should be spell checked.
Finally all markdown files are now treated as UTF-8 which should fix a problem that Windows users may have been seeing when checking files that contain non-ascii text, such as words with diacritics or basically anything that is not in Latin script. Which brings us to the next topic…
🔗 Support for RStudio Dictionaries
The spelling and hunspell packages require a dictionary for spell checking text in a given language. By default we include en-US and en-GB, but installing additional dictionaries has become even easier. The package will now automatically find dictionaries that you have installed in RStudio:
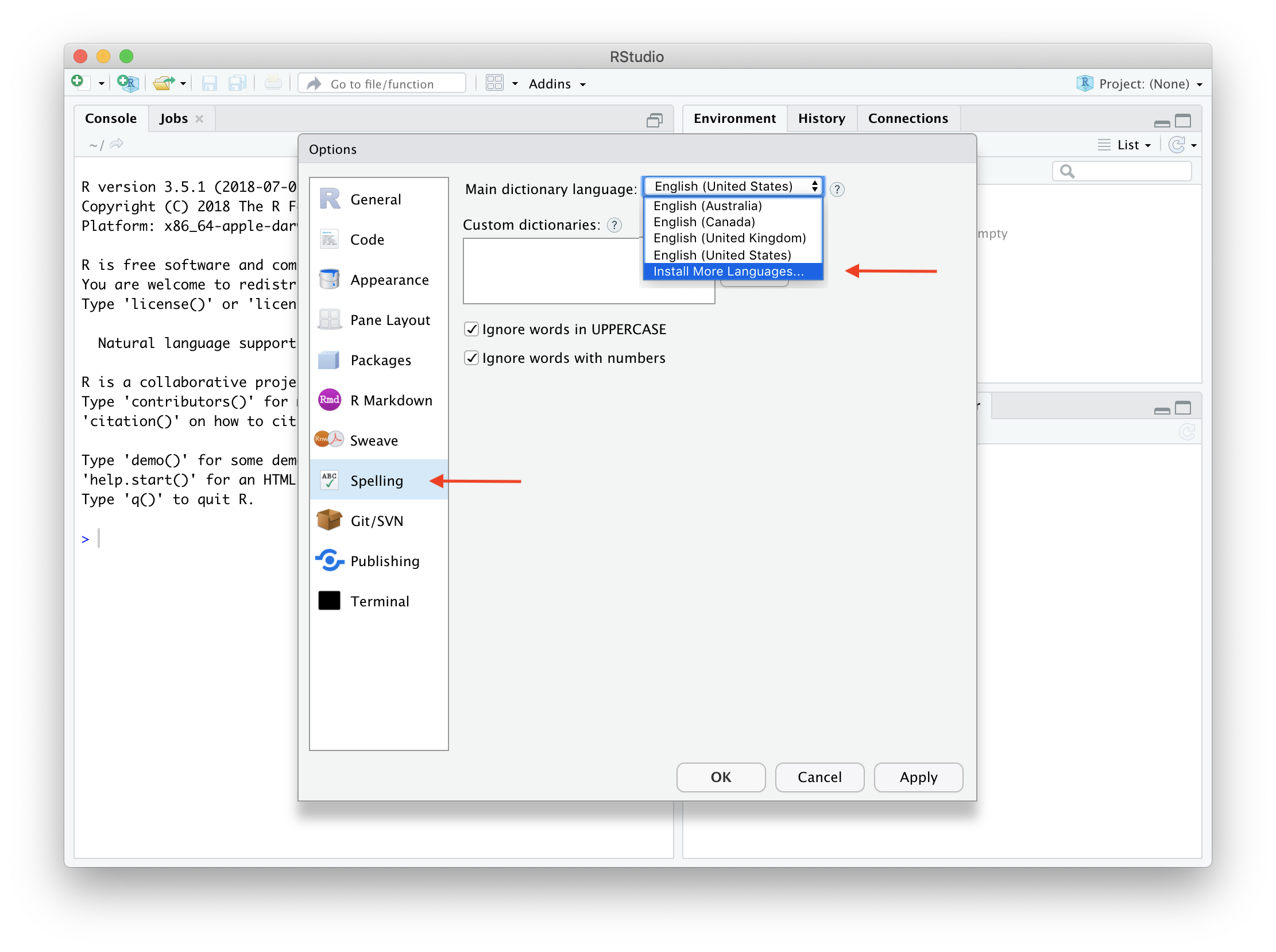
The RStudio IDE has a menu to install additional languages (Global Options -> Spelling -> Main Dictionary Language -> Install). The installed dictionaries will automatically become available to hunspell and you can use them in all hunspell/spelling functions that take a lang or dict argument.
hunspell::list_dictionaries()
# [1] "bg_BG" "ca_ES" "cs_CZ" "da_DK" "de_DE_neu" "de_DE" "el_GR"
# [8] "en_AU" "en_CA" "en_GB" "en_US" "es_ES" "fr_FR" "hr_HR"
# [15] "hu-HU" "id_ID" "it_IT" "lt_LT" "lv_LV" "nb_NO" "nl_NL"
# [22] "pl_PL" "pt_BR" "pt_PT" "ro_RO" "ru_RU" "sh" "sk_SK"
# [29] "sl_SI" "sr" "sv_SE" "uk_UA" "vi_VN"
hunspell::hunspell("Nou breekt mijn klomp!", dict = 'nl_NL')
# character(0)
Not using RStudio? The last chapter of the hunspell vignette explains in detail how to install dictionaries on different platforms.
🔗 Low Level Hunspell Updates
Text analysis experts might notice some significant improvements in hunspell because it includes the latest libhunspell 1.7 library. This version has lots of new features and bug fixes by László Németh.
Among the changes are performance enhancements and tweaks in the suggestion algorithm, i.e. the hunspell::hunspell_suggest() function in R. For a complete overview of changes have a look at the release notes from libhunspell.
Also we have updates the en-US and en-GB dictionaries included with the hunspell package to the latest version 2018.11.01 from libreoffice. This update include many new words that may have been previously marked as spelling errors.
Filed under
Suggest an edit
Open a pull request
