
Thursday, January 10, 2019 From rOpenSci (https://ropensci.org/blog/2019/01/10/vitae/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
🔗 Why vitae?

The process of maintaining a CV can be tedious. It’s a task I often forget about - that is until someone requests it and I find that my latest is woefully out of date. To make matters worse, these professional updates often need repeating across variety of sites (such as ORCID and LinkedIn).
Having seen several CVs put together into an R Markdown document (including my own, featuring a few quick and dirty hacks to make it work), the need for an R package was obvious. With many attendees of the 2018 rOpenSci OzUnconf having converted their CV to use R Markdown, the conference was the perfect space to develop and formalise the ideas that many of us have worked on independently in the past. Progress on the vitae package progressed much faster than expected, in fact it took less time to produce a functional prototype than it did to tidy the data for the ozbabynames package! The vitae project was primarily worked on by myself (@mitchoharawild) and Rob Hyndman (@robjhyndman), with ideas/discussion from many other participants.
The vitae package leverages the dynamic nature of R Markdown to quickly produce and update CV entries from a variety of data sources. With use of the included templates, examples and helper functions, it should be possible to produce a reasonable looking and data-driven CV in less than an hour.
Based on the twitter community’s response to the package announcement, CV maintenance is just as unenjoyable for others as it is for me! Hopefully this package makes it a little bit easier.
🔗 Keeping it simple
When developing an R package, it is easy to focus on features that are specific to your needs. Without concern for the interface, adding an abundance of specific features can make the package less useful overall. The vitae package is an excellent example of simpler is better, and less is more. vitae helps users to create a CV populated with data from ORCID, Google Scholar, local spreadsheets, online databases, CRAN, and endless others. However the vitae package does not directly provide functionality for any of these features, instead it relies on a common data format (a data-like object, such as a data.frame or tibble).
This allows vitae to integrate seamlessly with other R packages to pull in data for the CV.
- Want to get publications from ORCID? Try the rorcid package!
- How about Google Scholar? Heard of scholar?
- Have a few CRAN packages? Include them with pkgsearch.
- Employment history from LinkedIn? Well, I can’t find a working package for that yet. Someone reading this, please get on that!
Another example of simplicity being best is the interface used to add CV entries. Initially, we hastily started work on a function that produced entries for education. We created an education function, with some context specific arguments such as degree, institution and awards. However when it came to adding functions for professional experiences and related fields, we found that the resulting output was essentially the same. These CV entries could be simplified into a more generic detailed_entries function, that accepts more general arguments of what, when, with, where and why. The usage of these functions is now separated from a specific purpose, giving flexibility to use these functions for any CV section. Similar can be said for entries relating to awards and achievements, where the brief_entries function can be used to include less detailed sections.
As an added bonus, simpler design decisions makes the package easier to learn, and easier to develop!
🔗 vitae for R
The vitae package is now available on CRAN, making it easy to install with:
install.packages("vitae")
In version 0.1.0, the vitae package provides four commonly used LaTeX CV templates that have been modified for use with R Markdown. With the vitae package installed, CV templates can be accessed from the RStudio R Markdown template selector:
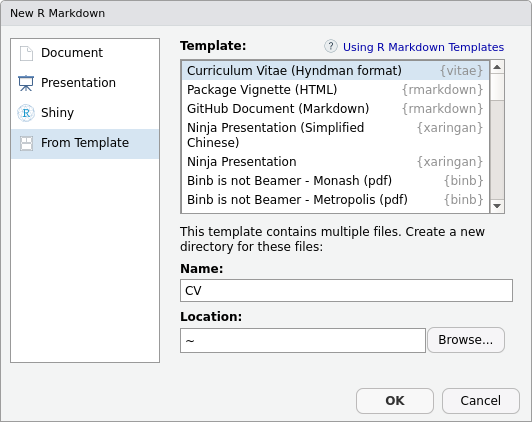
Like other R Markdown documents, the file is split into two sections: the YAML header, and the main body.
---
name: Mitchell O'Hara-Wild
date: "`r format(Sys.time(), '%B, %Y')`"
qualifications: BCom(Hons), BSc
address: Melbourne, Australia
profilepic: pic.jpg
email: [email protected]
www: mitchelloharawild.com
github: mitchelloharawild
linkedin: mitchelloharawild
twitter: mitchoharawild
headcolor: 414141
output: vitae::awesomecv
---
```r
knitr::opts_chunk$set(echo = FALSE, warning = FALSE, message = FALSE)
library(vitae)
```
# Professional Summary
This is a good opportunity to introduce yourself professionally and summarise
why your skills are well suited to the job you are applying for!
The YAML header contains general entries that are common across many templates, such as your name, address and social media profiles. You can also see that the output is set to vitae::awesomecv, which indicates that this CV uses the Awesome CV template.
The main body of the document contains standard R Markdown code, which is being used to set some document options, load the vitae package, and add a professional summary to the CV.
Let’s add to the main body with some education history. These details are available on ORCID with my ID of 0000-0001-6729-7695, which can be dynamically accessed using the rorcid package.
library(vitae)
edu <- do.call("rbind",
rorcid::orcid_educations("0000-0001-6729-7695")$`0000-0001-6729-7695`$`affiliation-group`$summaries
)
edu %>%
detailed_entries(
what = `education-summary.role-title`,
when = glue::glue("{`education-summary.start-date.year.value`} - {`education-summary.end-date.year.value`}"),
with = `education-summary.organization.name`,
where = `education-summary.organization.address.city`
)
The CV entries functions from vitae using a similar syntax to dplyr::mutate, where data manipulation can occur within the detailed_entries function. This is used above to combine the starting and ending year of my educations using the glue package. Also note that I have not specified anything for why here. Any of the arguments can be excluded, which will result in the corresponding CV field being left empty.
Knitting the document will generate the CV with up to date data directly from ORCID.

To learn more about how vitae can be used to automate your CV this year, the Introduction to vitae vignette is a great place to begin.
🔗 Contributing to vitae
Résumé/CV templates are abundantly available in many varieties of themes and layouts. The vitae package provides a few of the more popular templates that are suitable for most resumes. The included templates are far from comprehensive - your favourite template may not be included, or perhaps you have created your own template.
The vitae package has been developed in a way that makes extending it to support new templates simple! If you use a template that you’d like to convert for usage with vitae, the package includes a vignette for Creating vignette templates.
You can then make your converted template available for anyone to use via a pull request to the project’s GitHub repository: https://github.com/ropenscilabs/vitae
Filed under
Suggest an edit
Open a pull request
