
Tuesday, May 14, 2019 From rOpenSci (https://ropensci.org/blog/2019/05/14/nasapower/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
NASA generates and provides heaps of data to the scientific community. Not all of it is looking out at the stars. Some of it is looking back at us here on Earth. NASA’s Earth science program observes, understands and models the Earth system1. We can use these data to discover how our Earth is changing, to better predict change, and to understand the consequences for life on Earth.
The Earth science program includes the Prediction of Worldwide Energy Resource (POWER) project, which was initiated to improve upon the current renewable energy data set and to create new data sets from new satellite systems. The POWER project targets three user communities: 1) Renewable Energy (SSE), 2) Sustainable Buildings (SB) and 3) Agroclimatology (AG)1 and covers 140+ different parameters.
🔗 How Did This Package Happen?
I first became acquainted with the POWER data when I joined the GIS lab at the International Rice Research Institute (IRRI) in 2011. We commonly used the agroclimatology data from POWER to map and model rice projects. In most of the work I did, I used it with the EPIRICE model2, but it was also used for other crop modelling. Since then I have used the POWER data in projects with EPIRICE myself3 and have worked with other researchers who use it for crop simulation modelling exercises4,5. The data were a great resource for agricultural modelling, even if it was a bit coarse at 1˚ x 1˚ (covering roughly 12225 km2 or 4721 mi2 per grid cell at the equator, more as you approach the poles), the full data set had global coverage, offering data where we often needed it in areas that lacked good weather station coverage.
Because I had used the data and I knew plenty of others used the data; in 2017 I started writing nasapower6,7 to interface with the POWER website and run queries to get the data from the server but only for agricultural weather data (AG community), as this was my main (really only) interest. This created a simplified procedure for downloading the data in place of using the point and click interface of the website for repeated queries. I submitted it for review with rOpenSci and was happy with the feedback I received from the reviewers, quickly making the suggested changes.
🔗 What Happened Next
However, in late 2017 very shortly after the package was reviewed, the POWER team announced that the POWER data would be getting a makeover. The data would be served at 0.5˚ x 0.5˚ and use a new API to access them. This complicated things. I had never worked with an official API before. I had only worked with FTP servers, which are at best a very rudimentary API, but easy to work with in R. So I went back to the reviewers and editor and suggested that I needed to rewrite the whole package due to the major changes that were coming. The editor, Scott Chamberlain, readily agreed and over the next several months I learned how to write an R package that is an API client, a proper API client.
Thankfully rOpenSci has a great package, crul8, that makes this much easier. Even better, Maëlle Salmon had written a blog post on how to use it! So I got down to business writing the new version of nasapower using crul.
I quickly found out that the easy part was using crul; the hard part was validating user inputs. I decided early in the process of writing the package to validate the users’ input on the client side before even querying the server to make sure that only well-formed requests were sent. That way I could provide the user with feedback on what may have been entered incorrectly to make it easier for them to correct rather than relying on the server’s response.
There are over 140 different parameters for three “communities” (AG, SSE and SB), that the POWER data provides. One of the first issues I encountered was how to validate the users’ requests against what was available. Thankfully Ben Raymond found a JSON file that was served up for the API documentation that I was able to use to create an internal list object to check against, which made the parameters and communities easy to validate.
Formatting dates and checking those given all the different ways we enter them proved to be another challenge entirely taking nearly 100 lines of code.
Along with learning how to write an API client package, one of the methods I used in this package that I had not made full use of before was lists. Internally in that 100+ lines of code there are several inter-related checks and values that are provided for the query. By using lists I was able to return more than one value from a function after it was checked and validated and then provide that to the function I created to generate the request that crul sends, e.g., the longitude, latitude and whether it is a single point or region. By doing this I was able to simplify the parameters that the user had to enter when constructing a query in their R session because the API dictates by default many values that cannot co-occur.
🔗 Are We Doing it Right?
There were a few hang-ups along the way. At one point the POWER team
made a change to the API response while the package was in review.
Initially it provided an option for just a CSV file that was properly
rectangular. Suddenly it changed overnight with no warning to offering a
CSV file with information in a “header” as they called it. To me a
header in a CSV file is just column names. This was more. This was
metadata about the data itself. The quickest way to deal with this was
to simply read only the CSV file portion of the returned file. However,
I thought it might be useful to users to include the metadata that POWER
was now providing in this format as well. So I learned something else
new, how to modify the S3 print() method function to include the
metadata in the console along with the weather or climate data.
Later, in early 2019 I ran into an issue with the method I’d used to
validate user inputs for community when building the query that was
sent. Daniel Reis Pereira reported
that for some reason nasapower was failing to download 2 m wind data,
necessary for calculating evapotranspiration for crop modelling. Looking
into the JSON file I used as suggested by Ben Raymond, I found the issue. The
POWER team did not list the AG community as having this data available. I
contacted them thinking is was a mistake in the file since the data are in
indeed available. After some back and forth with the NASA-POWER team I never
really was clear on how I should handle this from their perspective aside from
their suggestion of just looking at their webpage to see what was available.
Additionally, when I checked, it appeared that the data were available for all
three communities. So I ended up dropping the check for community from the
user input validations because the community specified only affects the units
that the data are reported in, you can see the POWER documentation for more on
this. I still check user inputs for the correct parameter specification and
temporal matches, but assume all communities offer the same data. It’s not
optimal but until the POWER team can deliver a more robust way for us to check
against their records it will have to do.
🔗 Finally, It (Mostly?) Works!
The package is relatively simple as far as functionality. It only fetches data and reformats it for use in R or crop modelling software.
🔗 The Three Functions
The first function, get_power(), is the main function that is used and
offers the greatest flexibility. Say you want to know the maximum and
minimum temperatures for Death Valley in California, USA every day for
the last 35 years, you can easily do this with nasapower using
coordinates for the valley floor.
If you are not sure what the parameters are that you need to get the
data you can always have a look at the list of available parameters
using ?parameters. That shows that T2M_MIN and T2M_MAX
are the minimum and maximum temperatures at 2 meters. We will use those
to construct the query.
library(nasapower)
dv <- get_power(community = "AG",
lonlat = c(-117.2180, 36.7266),
dates = c("1983-01-01", "2018-12-31"),
temporal_average = "DAILY",
pars = c("T2M_MIN", "T2M_MAX"))
dv
## NASA/POWER SRB/FLASHFlux/MERRA2/GEOS 5.12.4 (FP-IT) 0.5 x 0.5 Degree Daily Averaged Data
## Dates (month/day/year): 01/01/1983 through 12/31/2018
## Location: Latitude 36.7266 Longitude -117.218
## Elevation from MERRA-2: Average for 1/2x1/2 degree lat/lon region = 1192.53 meters Site = na
## Climate zone: na (reference Briggs et al: http://www.energycodes.gov)
## Value for missing model data cannot be computed or out of model availability range: -99
##
## Parameters:
## T2M_MIN MERRA2 1/2x1/2 Minimum Temperature at 2 Meters (C) ;
## T2M_MAX MERRA2 1/2x1/2 Maximum Temperature at 2 Meters (C)
##
## # A tibble: 13,149 x 9
## LON LAT YEAR MM DD DOY YYYYMMDD T2M_MIN T2M_MAX
## <dbl> <dbl> <dbl> <int> <int> <int> <date> <dbl> <dbl>
## 1 -117. 36.7 1983 1 1 1 1983-01-01 -4.73 7.24
## 2 -117. 36.7 1983 1 2 2 1983-01-02 -3.33 7.72
## 3 -117. 36.7 1983 1 3 3 1983-01-03 0.05 11.8
## 4 -117. 36.7 1983 1 4 4 1983-01-04 1.27 14.9
## 5 -117. 36.7 1983 1 5 5 1983-01-05 2.55 15.9
## 6 -117. 36.7 1983 1 6 6 1983-01-06 2.63 17.1
## 7 -117. 36.7 1983 1 7 7 1983-01-07 3.2 17.2
## 8 -117. 36.7 1983 1 8 8 1983-01-08 1.96 18.3
## 9 -117. 36.7 1983 1 9 9 1983-01-09 0.7 14.0
## 10 -117. 36.7 1983 1 10 10 1983-01-10 1.3 17.6
## # … with 13,139 more rows
In the metadata header you can see information about where the data comes from and what dates have been queried and returned as well as the elevation data.
The tibble contains a few columns not in the original data, but that
can make it easier to work within R. The original data only include YEAR
and DOY. Looking at the data returned, there are:
LON = the queried longitude as a double;
LAT = the queried latitude as a double;
YEAR = the queried year as a double;
MM = the queried month as a double,
DD = the queried day as a double,
DOY = the day of year or Julian date as an integer,
YYYYMMDD = the full date as a date object and the requested parameters,
T2M_MIN = the minimum temperature at 2 meters above the Earth’s surface as a double, and
T2M_MAX = the maxiumum temperature at 2 meters above the Earth’s surface as a double.
🔗 Visualising the Data
To visualise these data I will use ggplot2, but first I need to gather the data
into long format using tidyr’s gather().
library(tidyr)
library(ggplot2)
library(hrbrthemes)
dv_long <-
tidyr::gather(dv, key = "T2M",
value = "Degrees",
c("T2M_MIN", "T2M_MAX"))
ggplot(dv_long, aes(x = YYYYMMDD, y = Degrees,
colour = Degrees)) +
geom_line() +
xlab("Year") +
ggtitle(label = "Death Valley, CA Daily Max and Min Temperatures",
sub = "Source: NASA POWER") +
scale_colour_viridis_c() +
theme_ipsum()
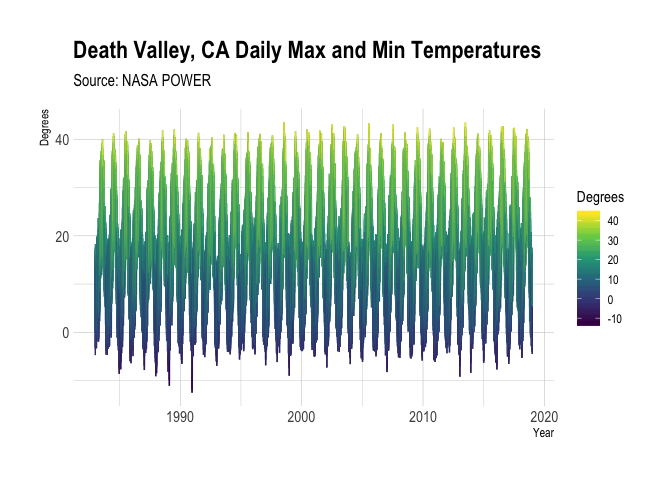
Figure 1: Daily temperature extremes at 2 meters above the Earth’s surface for the grid cell covering Death Valley, California, USA for the time-period from 1983 to 2018.
That is quite a swing in air temperatures from well over 40˚ C to well below 0˚ C throughout the year. I was going to put together a comparison with station data using GSODR9 but instead found a good reason why you might want to use nasapower to get POWER data. When I checked for stations nearby this specified point, there were two in the GSOD database, 746190-99999 and 999999-53139. However, neither one of them offers weather data for this time period. The station, 746190-99999, only offers data from 1982 to 1992 and 999999-53139 only provides data from 2004 to 2019. This nicely illustrates one of the advantages of the POWER data, it is available for any point on the globe. One of the weaknesses you might have noticed if you looked at the elevation data in the metadata header is that it shows the elevation of Death Valley is over 1000 m above sea level when we know that it is 86 m below sea level. This is due to the fact that the data are the average of a 0.5˚ by 0.5˚ area or roughly 3000 km2 as opposed to a single point that a station can provide.
🔗 Crop Modelling From Space
This can be advantageous as well, however. Some agricultural scientists work with models that predict crop yields in response to changes to the crop, weather, farmer inputs or even climate change. Crop yield modelling often uses daily weather data covering large relatively continuous areas that are less affected by things like elevation, so for these purposes, the POWER data can be very useful. Another reason the POWER data are useful could be that the same data set is available for many areas, making model output comparisons easier.
If you do any crop modelling work you are likely familiar with the
Decision Support System for Agrotechnology Transfer
DSSAT platform10, 11, 12. The new POWER API
provides properly formatted ICASA files,
which are the format that DSSAT uses. Naturally I took advantage of this and
added a function, create_icasa(), to download and save ICASA files for use in
crop simulations.
But, being in Toowoomba, Queensland, I had to acknowledge another crop
simulation model, the Agricultural Production Systems sIMulator
APSIM13. APSIM was developed here and has similar
functionality to DSSAT. However, the POWER API did not offer properly formatted
APSIM .met files. So, wrote a function, create_met(), that takes advantage of
the POWER data API and the R APSIM package 14 to generate the proper weather
.met files since many APSIM users, use R in their modelling pipeline, e.g.,
APSIMBatch15 and apsimr16.
Both of these functions simply download data and write the values to disk in a specialised file format that these crop modelling platforms use, therefore I have declined to illustrate their usage in this blog post.
🔗 There Is More Than Just Daily Data for Single Cells
🔗 Retrieving Climatology
Daily weather data are not the only data offered by this API. Two other options
exist for the temporal_average parameter, INTERANNUAL and CLIMATOLOGY.
INTERANNUAL data provide monthly averages for the same 0.5˚ x 0.5˚ grid as the
daily data for the time-period the user specifies, while CLIMATOLOGY provides
0.5˚ x 0.5˚ gridded data of a thirty year time period from January 1984 to
December 2013.
The CLIMATOLOGY data are the only way to get the entire surface in one query, but single cell and regional data are also available for this temporal average.
library(raster)
## Loading required package: sp
##
## Attaching package: 'raster'
## The following object is masked from 'package:tidyr':
##
## extract
library(viridisLite)
global_t2m <-
get_power(
community = "AG",
pars = "T2M",
temporal_average = "CLIMATOLOGY",
lonlat = "GLOBAL"
)
# view the tibble
global_t2m
## NASA/POWER SRB/FLASHFlux/MERRA2/GEOS 5.12.4 (FP-IT) 0.5 x 0.5 Degree Climatologies
## 22-year Additional Solar Parameter Monthly & Annual Climatologies (July 1983 - June 2005), 30-year Meteorological and Solar Monthly & Annual Climatologies (January 1984 - December 2013)
## Location: Global
## Value for missing model data cannot be computed or out of model availability range: -99
## Parameter(s):
## T2M MERRA2 1/2x1/2 Temperature at 2 Meters (C)
##
## Parameters:
## NA;
## NA;
## T2M MERRA2 1/2x1/2 Temperature at 2 Meters (C)
##
## # A tibble: 259,200 x 16
## LON LAT PARAMETER JAN FEB MAR APR MAY JUN JUL AUG
## <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 -180. -89.8 T2M -29.0 -40.7 -52.9 -57.8 -59.1 -59.6 -61.3 -61.8
## 2 -179. -89.8 T2M -29.0 -40.7 -52.9 -57.8 -59.1 -59.6 -61.3 -61.8
## 3 -179. -89.8 T2M -29.0 -40.7 -52.9 -57.8 -59.1 -59.6 -61.3 -61.8
## 4 -178. -89.8 T2M -29.0 -40.7 -52.9 -57.8 -59.1 -59.6 -61.3 -61.8
## 5 -178. -89.8 T2M -29.0 -40.7 -52.9 -57.8 -59.1 -59.6 -61.3 -61.8
## 6 -177. -89.8 T2M -28.9 -40.7 -52.9 -57.9 -59.1 -59.6 -61.3 -61.8
## 7 -177. -89.8 T2M -28.9 -40.7 -52.9 -57.9 -59.1 -59.6 -61.3 -61.8
## 8 -176. -89.8 T2M -28.9 -40.7 -53.0 -57.9 -59.1 -59.6 -61.3 -61.8
## 9 -176. -89.8 T2M -28.9 -40.7 -53.0 -57.9 -59.1 -59.6 -61.3 -61.8
## 10 -175. -89.8 T2M -28.9 -40.7 -53.0 -57.9 -59.1 -59.6 -61.3 -61.8
## # … with 259,190 more rows, and 5 more variables: SEP <dbl>, OCT <dbl>,
## # NOV <dbl>, DEC <dbl>, ANN <dbl>
# map only annual average temperatures by converting the 15th column to a raster
# object
T2M_ann <- rasterFromXYZ(
global_t2m[c(1:2, 16)],
crs = "+proj=eqc +lat_ts=0 +lat_0=0 +lon_0=0 +x_0=0 +y_0=0 +ellps=WGS84 +datum=WGS84 +units=m +no_defs")
# how many unique values
n <- length(unique(global_t2m$ANN))
# plot the annual average temperature using viridis
plot(T2M_ann, col = viridis(n = n), xlab = "Longitude", ylab = "Latitude")
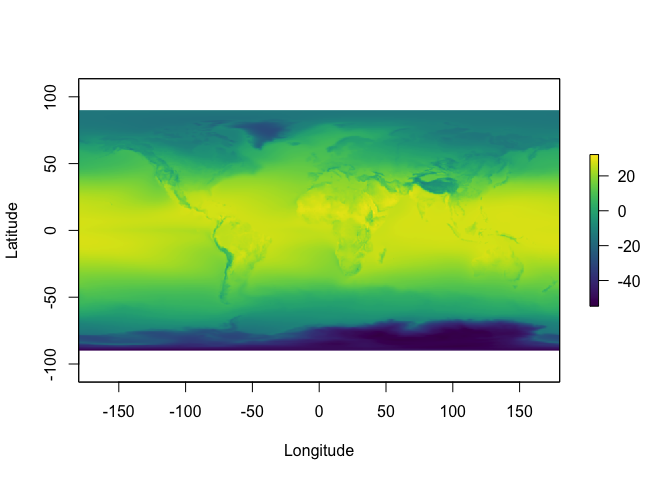
Figure 2: Global 30-year annual meteorological (January 1984 - December 2013) average temperature at 2 meters above the Earth’s surface modelled from satellite derived data. You can mostly make out the outlines of the continents and especially the mountain ranges such as the Andes and Rocky Mountains to the left and the Tibetan plateau at about 100˚ longitude (x-axis) and 45˚ latitude (y-axis)
🔗 Retrieving Regional Data
If your interests cover a large area, it is possible to retrieve an area of
cells, rather than a single cell in a query. They can not be more than 100
points in total for an area of 4.5˚ x 4.5˚. Regional coverage is simply
specified by providing a bounding box as “lower left (lon, lat)” and “upper
right (lon, lat)” coordinates, i.e., lonlat = c(xmin, ymin, xmax, ymax) in
that order for a given region, e.g., a bounding box for the south-western
corner of Australia:
lonlat = c(112.5, -55.5, 115.5, -50.5).
regional_t2m <-
get_power(
community = "AG",
pars = "T2M",
temporal_average = "CLIMATOLOGY",
lonlat = c(112.5, -55.5, 115.5, -50.5)
)
# view the tibble
regional_t2m
## NASA/POWER SRB/FLASHFlux/MERRA2/ 0.5 x 0.5 Degree Climatologies
## 22-year Additional Solar Parameter Monthly & Annual Climatologies (July 1983 - June 2005), 30-year Meteorological and Solar Monthly & Annual Climatologies (January 1984 - December 2013)
## Location: Regional
## Elevation from MERRA-2: Average for 1/2x1/2 degree lat/lon region = na meters Site = na
## Climate zone: na (reference Briggs et al: http://www.energycodes.gov)
## Value for missing model data cannot be computed or out of model availability range: -99
##
## Parameters:
## T2M MERRA2 1/2x1/2 Temperature at 2 Meters (C)
##
## # A tibble: 77 x 16
## LON LAT PARAMETER JAN FEB MAR APR MAY JUN JUL AUG
## <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 113. -55.2 T2M 2.98 3.38 3.13 2.4 1.65 1.01 0.41 -0.05
## 2 113. -55.2 T2M 3.07 3.47 3.22 2.5 1.75 1.11 0.51 0.05
## 3 114. -55.2 T2M 3.14 3.55 3.32 2.6 1.85 1.21 0.61 0.15
## 4 114. -55.2 T2M 3.2 3.62 3.39 2.69 1.94 1.29 0.69 0.22
## 5 115. -55.2 T2M 3.26 3.69 3.46 2.76 2.01 1.37 0.77 0.28
## 6 115. -55.2 T2M 3.3 3.73 3.51 2.82 2.06 1.43 0.83 0.34
## 7 116. -55.2 T2M 3.32 3.77 3.54 2.86 2.1 1.49 0.88 0.39
## 8 113. -54.8 T2M 3.12 3.51 3.3 2.57 1.82 1.17 0.59 0.12
## 9 113. -54.8 T2M 3.2 3.6 3.39 2.68 1.92 1.26 0.69 0.21
## 10 114. -54.8 T2M 3.27 3.7 3.49 2.78 2.02 1.36 0.78 0.3
## # … with 67 more rows, and 5 more variables: SEP <dbl>, OCT <dbl>,
## # NOV <dbl>, DEC <dbl>, ANN <dbl>
# map only annual average temperatures by converting the 15th column to a raster
# object
T2M_ann_regional <- rasterFromXYZ(
regional_t2m[c(1:2, 16)],
crs = "+proj=eqc +lat_ts=0 +lat_0=0 +lon_0=0 +x_0=0 +y_0=0 +ellps=WGS84 +datum=WGS84 +units=m +no_defs")
# how many unique values
n <- length(unique(regional_t2m$ANN))
# plot the annual average temperature using viridis
plot(T2M_ann_regional, col = viridis(n = n), xlab = "Longitude", ylab = "Latitude")
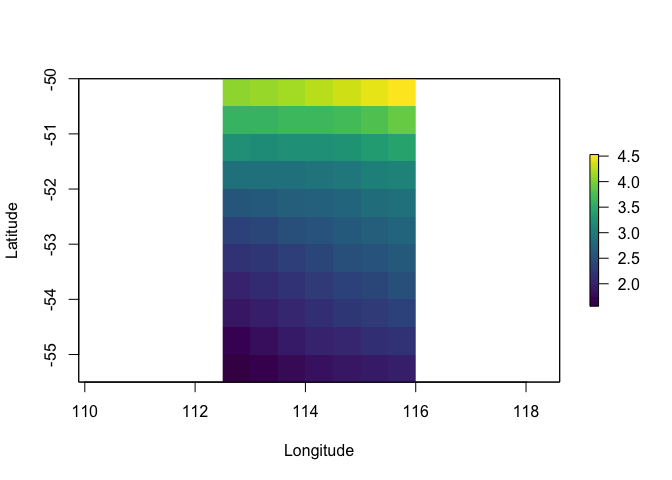
Figure 3: Regional 30-year annual meteorological (January 1984 - December 2013) average temperature at 2 meters above the Earth’s surface modelled from satellite derived data for the south-western coastal area of Australia, illustrating the maximum allowable cells in a regional query
As you can see, because the data are georeferenced it is easy to use them in R’s spatial packages including sf and raster. Emerson Del Ponte, (@edelponte), used the data in a talk at the International Congress of Plant Pathology in August 2018, “Can Rainfall be a Useful Predictor of Epidemic Risk Across Temporal and Spatial Scales?”, see slides 23, 24 and 25 for maps created using nasapower and the POWER data for two states in Brazil. These maps took a bit more work to query the API and generate, but I plan to add an example vignette detailing how this can be done in a future release.
🔗 Conclusion
Even though the package took me well over one year to write and work out all of the bugs and has only three functions, I learned quite a bit from the experience. The new API really does improve the ability for a developer to write a client to interface with the data. Now the nasapower package is able to access all of the data available whereas the initial version was only able to work with the “AG” community data.
While nasapower does not redistribute the data or provide it in any way, if you use the data, we encourage users to follow the requests of the POWER Project Team.
When POWER data products are used in a publication, we request the following acknowledgement be included: “These data were obtained from the NASA Langley Research Center POWER Project funded through the NASA Earth Science Directorate Applied Science Program.”
The approach I have used mostly works, but there has been at least one
example where data are listed as being available in the POWER database
but querying by the apparently proper pars does not work, see Issue
#34. Because of
issues like this, in what appear to be edge cases, I suggest checking
the web interface if you experience difficulties querying data.
Hopefully the API itself has settled out a bit and will not have the
sudden changes that I experienced. The POWER team have been supportive
of the package, and I have received feedback and interaction from other
users along the way that helped me by finding and reporting bugs.
🔗 Acknowledgements
I would like to recognise the valuable comments from Emerson Del Ponte and Paul Melloy on this blog post. Most of all, I appreciate the rOpenSci review process with valuable contributions from Hazel Kavılı, Alison Boyer and of course my ever-patient editor and third reviewer, Scott Chamberlain. I welcome further feedback for issues and suggestions, they have only made this package better. If you are interested in this or want to know more about how to use the package, I encourage you to browse the vignette and other on-line documentation, https://docs.ropensci.org/nasapower//articles/nasapower.html.
Stackhouse, Paul W., Jr., Taiping Zhang, David Westberg, A. Jason Barnett, Tyler Bristow, Bradley Macpherson, and James M. Hoell. 2018. “POWER Release 8 (with GIS Applications) Methodology (Data Parameters, Sources, & Validation)”, Data Version 8.0.1. NASA. https://power.larc.nasa.gov/documents/POWER_Data_v8_methodology.pdf. ↩︎ ↩︎
Savary, Serge, Andrew Nelson, Laetitia Willocquet, Ireneo Pangga, and Jorrel Aunario. 2012. “Modeling and Mapping Potential Epidemics of Rice Diseases Globally.” Crop Protection 34 (Supplement C): 6–17. https://doi.org/10.1016/j.cropro.2011.11.009. ↩︎
Duku, Confidence, Adam H. Sparks, and Sander J. Zwart. 2016. “Spatial Modelling of Rice Yield Losses in Tanzania Due to Bacterial Leaf Blight and Leaf Blast in a Changing Climate.” Climatic Change 135 (3): 569–83. https://doi.org/10.1007/s10584-015-1580-2. ↩︎
van Wart, Justin, Patricio Grassini, and Kenneth G. Cassman. 2013. “Impact of Derived Global Weather Data on Simulated Crop Yields.” Global Change Biology 19 (12): 3822–34. https://doi.org/10.1111/gcb.12302. ↩︎
van Wart, Justin, Patricio Grassini, Haishun Yang, Lieven Claessens, Andrew Jarvis, and Kenneth G. Cassman. 2015. “Creating Long-Term Weather Data from Thin Air for Crop Simulation Modeling.” Agricultural and Forest Meteorology 209-210 (Supplement C): 49–58. https://doi.org/10.1016/j.agrformet.2015.02.020. ↩︎
Sparks, Adam, 2018. “nasapower: A NASA POWER Global Meteorology, Surface Solar Energy and Climatology Data Client for R”. Journal of Open Source Software, 3(30), 1035, https://doi.org/10.21105/joss.01035. ↩︎
Sparks, Adam. 2019. “nasapower: NASA-POWER Data from R”. R package version 1.1.1, https://docs.ropensci.org/nasapower//. ↩︎
Chamberlain, Scott. 2018. “crul: HTTP Client”. rOpenSci. https://CRAN.R-project.org/package=crul. ↩︎
Sparks, Adam H., Tomislav Hengl and Andrew Nelson. 2017. “GSODR: Global Summary Daily Weather Data in R”. The Journal of Open Source Software, 2(10). https://doi.org/10.21105/joss.00177. ↩︎
Jones, J. W., G. Y. Tsuji, G. Hoogenboom, L. A. Hunt, P. K. Thornton, P. W. Wilkens, D. T. Imamura, W. T. Bowen, and U. Singh. 1998. “Decision Support System for Agrotechnology Transfer: DSSAT v3.” In Understanding Options for Agricultural Production, 157–77. Springer. ↩︎
Jones, James W, Gerrit Hoogenboom, Cheryl H Porter, Ken J Boote, William D Batchelor, LA Hunt, Paul W Wilkens, Upendra Singh, Arjan J Gijsman, and Joe T Ritchie. 2003. “The DSSAT Cropping System Model.” European Journal of Agronomy 18 (3-4): 235–65. ↩︎
Hoogenboom, G, CH Porter, V Shelia, KJ Boote, U Singh, JW White, LA Hunt, et al. 2017. “Decision Support System for Agrotechnology Transfer (DSSAT) Version 4.7 https://dssat.net. DSSAT Foundation, Gainesville, Florida.” USA. ↩︎
Keating, Brian A., Peter S. Carberry, Graeme L. Hammer, Mervyn E. Probert, Michael J. Robertson, D. Holzworth, Neil I. Huth, et al. 2003. “An Overview of APSIM, a Model Designed for Farming Systems Simulation.” European Journal of Agronomy 18 (3-4): 267–88. ↩︎
Fainges, Justin. 2017. “APSIM: General Utility Functions for the ’Agricultural Production Systems Simulator’". CSIRO. https://CRAN.R-project.org/package=APSIM. ↩︎
Bangyou Zheng (2012). “APSIMBatch: Analysis the output of Apsim software.” R package version 0.1.0.2374. https://CRAN.R-project.org/package=APSIMBatch ↩︎
Bryan Stanfill (2015). “apsimr: Edit, Run and Evaluate APSIM Simulations Easily Using R”. R package version 1.2. https://CRAN.R-project.org/package=apsimr ↩︎
Filed under
Suggest an edit
Open a pull request
