
Tuesday, September 22, 2020 From rOpenSci (https://ropensci.org/blog/2020/09/22/treedata.table/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
The data.table package enables high-performance extended functionality for data tables in R. treedata.table is a wrapper for data.table for phylogenetic analyses that matches a phylogeny to the data.table, and preserves matching during data.table operations. Using the data.table package greatly increases analysis reproducibility and the efficiency of data manipulation operations over other ways of performing similar tasks in base R, enabling processing of larger trees and datasets.
🔗 Why use treedata.table?
Simultaneous processing of phylogenetic trees and data remains a computationally-intensive task. For example, processing a tree alongside a dataset of phylogenetic characters means processing much more data compared to processing the characters alone. This results in much longer processing times compared to more simple analysis with characters alone in data.table (Fig. 1A). treedata.table provides new tools for increasing the speed and efficiency of phylogenetic data processing. Data manipulation in treedata.table is significantly faster than in other commonly used packages such as base (>35%), treeplyr (>60%), and dplyr (>90%). Additionally, treedata.table is >400% faster than treeplyr during the initial data/tree matching step (Fig. 1B).
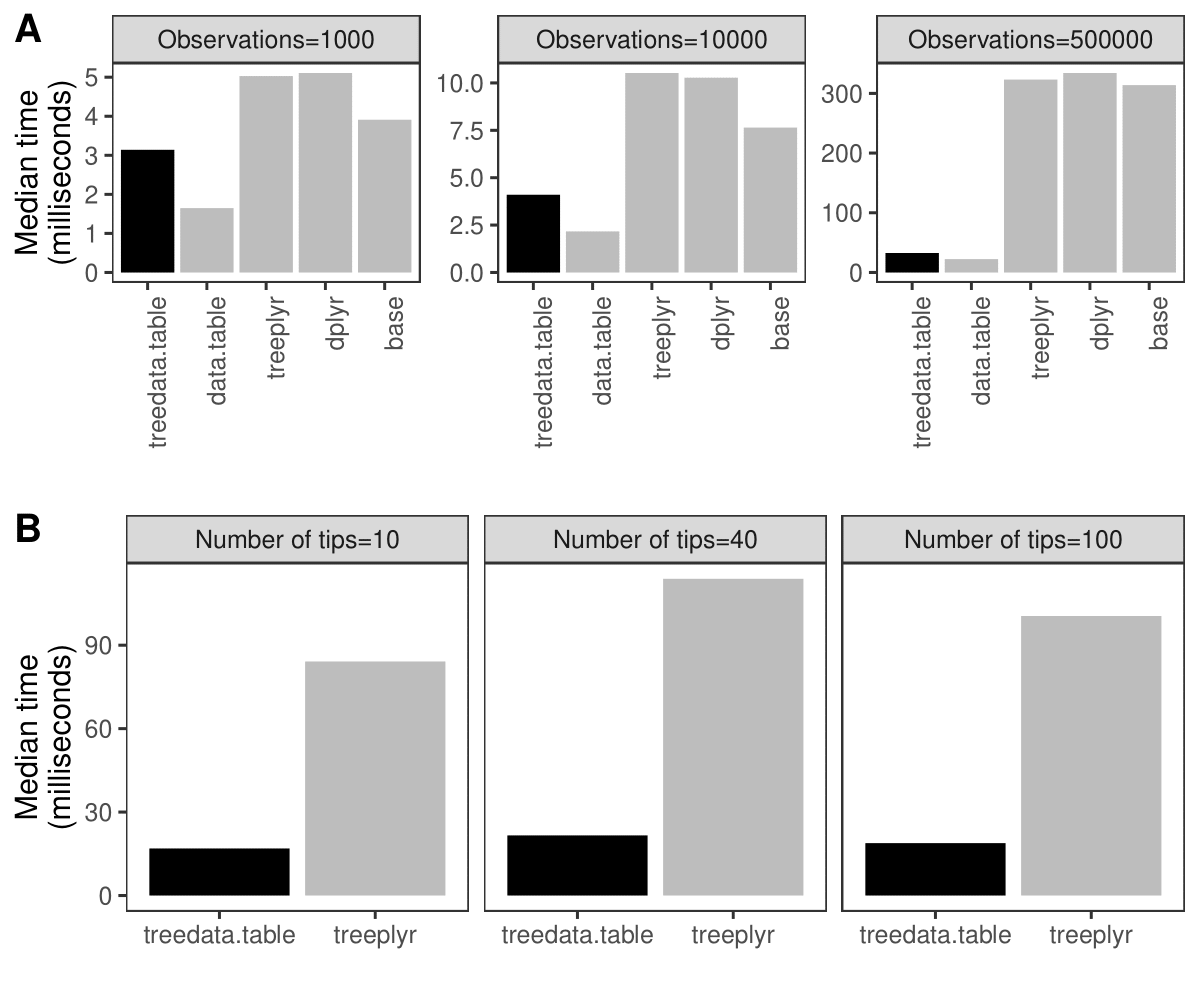
Fig. 1. Results for the treedata.table microbenchmark during (A) data manipulation (treedata.table) and (B) tree/data matching steps. We compare the performance of treedata.table against data.table, base, treeplyr, and dplyr using the microbenchmark R package.
🔗 What can I do in treedata.table?
The simplest function that can be done in treedata.table is matching the tips of a phylogenetic tree to the rows in a data.table object. Like many R packages involving phylogenetic trees, treedata.table assumes that your tree is an object of class phylo. The first vignette (in English here and Spanish here) walks new users through matching a phylogeny to a data.table, and performing some common data operations, such as selecting data columns and dropping tips that do not have data. There are other ways to achieve similar results, but as seen on Fig. 1, these are not as efficient.
Something unique in treedata.table is the ability to work with multiPhylo objects. multiPhylo objects, as their name suggests, are colelctions of trees. For example, perhaps you would like to match all the trees in a Bayesian posterior sample to a dataset to perform a comparative methods analysis for every tree in your sample. Our second vignette walks researchers through the process of syncing many trees to one dataset, manipulating the data, and performing a continuous trait evolution modeling exercise in geiger.
Our other two vignettes cover important data functions researchers may wish to do with phylogenetic data. For example, syncing names across datasets and phylogenetic trees based on partial matching, and assorted data tidying functions.
🔗 Where did treedata.table come from?

Fig. 2. The beach outside the workshop bunkhouse.
treedata.table is a research output from the Nantucket DevelopR workshop. Funded by an NSF grant to Liam Revell, the workshop aimed to support intermediate R developers working with phylogenetic and phylogenetic comparative methods. Last time around, we had four instructors (April Wright, Josef Uyeda, Claudia Solis-Lemus and Klaus Schliep). Each instructor taught one serious lesson during the week, and most did one “fireside chat” about being a computational scientist working in R.
But the real heart of the workshop was spending the day immersed in coding, both collaboratively and alone. Participants each came with a project in mind, and made pitches to others for their project. Some participants worked on multiple projects, or one with a group and one alone. The instructors were housed separately, and often we’d show up to the beachside house to find everyone didn’t want lecture yet - they were too busy working already. Intermediate programmers are often sort of left to their own devices in education, and spending a week developing skills, community, and friendships was absolutely lovely. And, as evidenced by this package, productive!
🔗 Acknowledgements
We’d like to thank all the participants at the workshop for a very special week together in an amazing place. We would also like to thank the instructors (Claudia and Klaus), Liam (NSF DBI-1759940), UMass field station coordinator Yolanda Vaillancourt, and course facilitator Fabio Machado Lugar. treedata.table is an rOpenSci peer-reviewed package. We would also like to thank package reviewers Hugo Gruson, Kari Norman, editor Julia Gustavson and blog editor Steffi LaZerte. AMW was supported by an Institutional Development Award (IDeA) from the National Institute of General Medical Sciences of the National Institutes of Health under grant number P2O GM103424-18.
Filed under
Suggest an edit
Open a pull request
