
Tuesday, July 27, 2021 From rOpenSci (https://ropensci.org/blog/2021/07/27/censo2017/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
🔗 Summary
censo2017 is an R package designed to organize the Redatam1 files provided by the Chilean National Bureau of Statistics (Instituto Nacional de Estadísticas de Chile in spanish) in DVD format2. This package was inspired by citesdb (Noam Ross, 2020) and taxadb (Carl Boettiger et al, 2021). This post is about this package, the problem it solves, how to use it, and the fact that the package and its review process were all in Spanish.
🔗 The census challenge
The motivation to have completed this is that, almost two years ago now, I had to complete an assignment that required me to extract data from the aforementioned DVD and it got very complicated.
I had to borrow a Windows laptop and get an external DVD reader in order to read those REDATAM files to obtain a few population summaries with specific software for that format. To my surprise, the task started to get more and more challenging, to the point that I wanted to export the data to SQL for easier data extraction.
My goal wasn’t to extract statistical secrets, which is not possible with these datasets, I just wanted to obtain values of population by age intervals for different regions, among other similar aggregations, which is something that dplyr and other tools ease a lot. After being able to convert the datasets and the description of variables to CSV/XML, I found that the effort in doing that justified creating an R package to organize my work.
🔗 The long way to simplicity
The REDATAM Converter (Pablo De Grande, 2016) allows exporting complete REDATAM databases as CSV for use in, for example, R or Python. Unfortunately, this tool is also Windows-only, and as a Linux user I wanted to make the census datasets easily available for all platforms.
Besides REDATAM, using CSV for a census is not the best choice, as that involves reading 4 GB tables from disk. This is so big that most laptops won’t be able to perform joins, no matter what tool you use (R, Python or sub-tools such as readr or data.table, just to mention a few excellent tools). However, using a SQL based tool, such as DuckDB, allows efficient querying and makes most census operations possible on a common laptop.
censo2017 creates a local and embedded DuckDB database that simplifies analysis of the census datasets. It allows efficient querying and is accessible via a DBI compatible interface. The package also provides an interactive pane for RStudio that allows exploring the database and previewing data. The ultimate goal of this work is to ease data access for researchers in Humanities and Social Sciences.
🔗 How does censo2017 work?
For a quick illustration, assume we haven’t already installed the package and the local database, which are two separate steps.
# install, load the package and create the local database
remotes::install_github("ropensci/censo2017")
library(censo2017)
censo_descargar()
# to be able to use collect() and use regular expressions
library(dplyr)
We know there are roughly 17 million inhabitants in Chile, but how many of them are men/women? How old are Chileans? How many of them attended university/community college? How many of them work on each branch of economic activity3? Census questions “p08”, “p09”, “p15” and “p18” tell us this information.
This package features a metadata table (variables) which is not a part of the original files, as it was inferred from the REDATAM structure, that tells us to which table each variable belongs. For example, by using dplyr we can look for descriptions that match “Curso” (Course).
tbl(censo_conectar(), "variables") %>%
collect() %>%
filter(grepl("Curso", descripcion))
tabla variable descripcion tipo rango
<chr> <chr> <chr> <chr> <chr>
1 personas p14 Curso o Año Más Alto Aprobado integer 0 - 8
2 personas p15 Nivel del Curso Más Alto Aprobado integer 1 - 14
Those who are familiar with these codes might remember each value for “p15”, but fortunately for the rest of us, this package also attaches the labels, so any user can see that “p15 = 12” means “the person attended university”.
tbl(censo_conectar(), "variables_codificacion") %>%
collect() %>%
filter(variable == "p15")
tabla variable valor descripcion
<chr> <chr> <int> <chr>
1 personas p15 1 Sala Cuna o Jardín Infantil
2 personas p15 2 Prekínder
3 personas p15 3 Kínder
4 personas p15 4 Especial o Diferencial
5 personas p15 5 Educación Básica
6 personas p15 6 Primaria o Preparatoria (Sistema Antiguo)
7 personas p15 7 Científico-Humanista
8 personas p15 8 Técnica Profesional
9 personas p15 9 Humanidades (Sistema Antiguo)
10 personas p15 10 Técnica Comercial, Industrial/Normalista (Sistema Antiguo)
11 personas p15 11 Técnico Superior (1-3 Años)
12 personas p15 12 Profesional (4 o Más Años)
13 personas p15 13 Magíster
14 personas p15 14 Doctorado
15 personas p15 99 Valor Perdido
16 personas p15 98 No Aplica
To get detailed information for each commune/region regarding the questions above, we need to think of the REDATAM data as a tree, and it is necessary to join “zonas” (zones) with “viviendas” (dwellings) by zone ID, then join “viviendas” with “hogares” (households) by dwelling ID, and then “hogares” with “personas” (people) by household ID. This is done in no time with the DuckDB backend.
personas <- tbl(censo_conectar(), "zonas") %>%
mutate(
region = substr(as.character(geocodigo), 1, 2),
comuna = substr(as.character(geocodigo), 1, 5)
) %>%
select(region, comuna, geocodigo, zonaloc_ref_id) %>%
inner_join(select(tbl(censo_conectar(), "viviendas"),
zonaloc_ref_id, vivienda_ref_id), by = "zonaloc_ref_id") %>%
inner_join(select(tbl(censo_conectar(), "hogares"), vivienda_ref_id,
hogar_ref_id), by = "vivienda_ref_id") %>%
inner_join(select(tbl(censo_conectar(), "personas"), hogar_ref_id,
p08, p15, p18), by = "hogar_ref_id") %>%
collect()
A quick verification can be obtained with a count. The resulting table makes perfect sense and it reflects common knowledge summary statistics, such as that in the capitol (region #13) there are around 7 million inhabitants.
personas %>%
group_by(region) %>%
count()
region n
<chr> <int>
1 01 330558
2 02 607534
3 03 286168
4 04 757586
5 05 1815902
6 06 914555
7 07 1044950
8 08 2037414
9 09 957224
10 10 828708
11 11 103158
12 12 166533
13 13 7112808
14 14 384837
15 15 226068
To get to know the share of men (1) and women (2) per region, the code is very similar.
personas %>%
group_by(region, p08) %>%
count() %>%
group_by(region) %>%
mutate(p = n / sum(n))
region p08 n p
<chr> <int> <int> <dbl>
1 01 1 167793 0.508
2 01 2 162765 0.492
3 02 1 315014 0.519
4 02 2 292520 0.481
5 03 1 144420 0.505
6 03 2 141748 0.495
7 04 1 368774 0.487
8 04 2 388812 0.513
9 05 1 880215 0.485
10 05 2 935687 0.515
# … with 20 more rows
At this point we obtained simple aggregations, but being R a language for statistics, you might be interested in doing inference. As an example, assume that the population follows a normal distribution, so that it makes sense to find the 95% confidence interval estimate of the difference between the male proportion of elderly people4 and the female proportion of non-elderly people, each within their own age group.
sex_vs_elder <- tbl(censo_conectar(), "personas") %>%
select(sex = p08, p09) %>%
mutate(elderly = ifelse(p09 >= 64, 1, 0)) %>%
group_by(sex, elderly) %>%
count() %>%
# labels re-arrangement, put here for efficiency
mutate(
elderly = ifelse(elderly == 1, "1. elderly", "2. non-elderly"),
sex = ifelse(sex == 1, "1. men", "2. women")
) %>%
ungroup() %>%
collect()
sex_vs_elder
sex elderly n
<chr> <chr> <dbl>
1 1. men 2. non-elderly 7666728
2 2. women 2. non-elderly 7751676
3 1. men 1. elderly 935261
4 2. women 1. elderly 1220338
Before conducting a proportions test, we need to re-shape the data and then proceed with the test.
xtabs(n ~ elderly + sex, sex_vs_elder)
sex
elderly 1. men 2. women
1. elderly 935261 1220338
2. non-elderly 7666728 7751676
prop.test(xtabs(n ~ elderly + sex, sex_vs_elder))
2-sample test for equality of proportions with continuity correction
data: xtabs(n ~ elderly + sex, sex_vs_elder)
X-squared = 30392, df = 1, p-value < 2.2e-16
alternative hypothesis: two.sided
95 percent confidence interval:
-0.06407740 -0.06266263
sample estimates:
prop 1 prop 2
0.4338752 0.4972452
The 95% confidence interval estimate of the difference between the proportion of male elders and non-elders is between -6.4% and -6.3%, which is in line with the fact that women tend to have a longer life expectancy in Chile (see Statista to compare). What I wanted to demonstrate here is that by using this package, it is very easy to pass data to R, so that you can conduct regression analysis or other statistical analyses on the Chilean population.
🔗 Using censo2017 with other packages
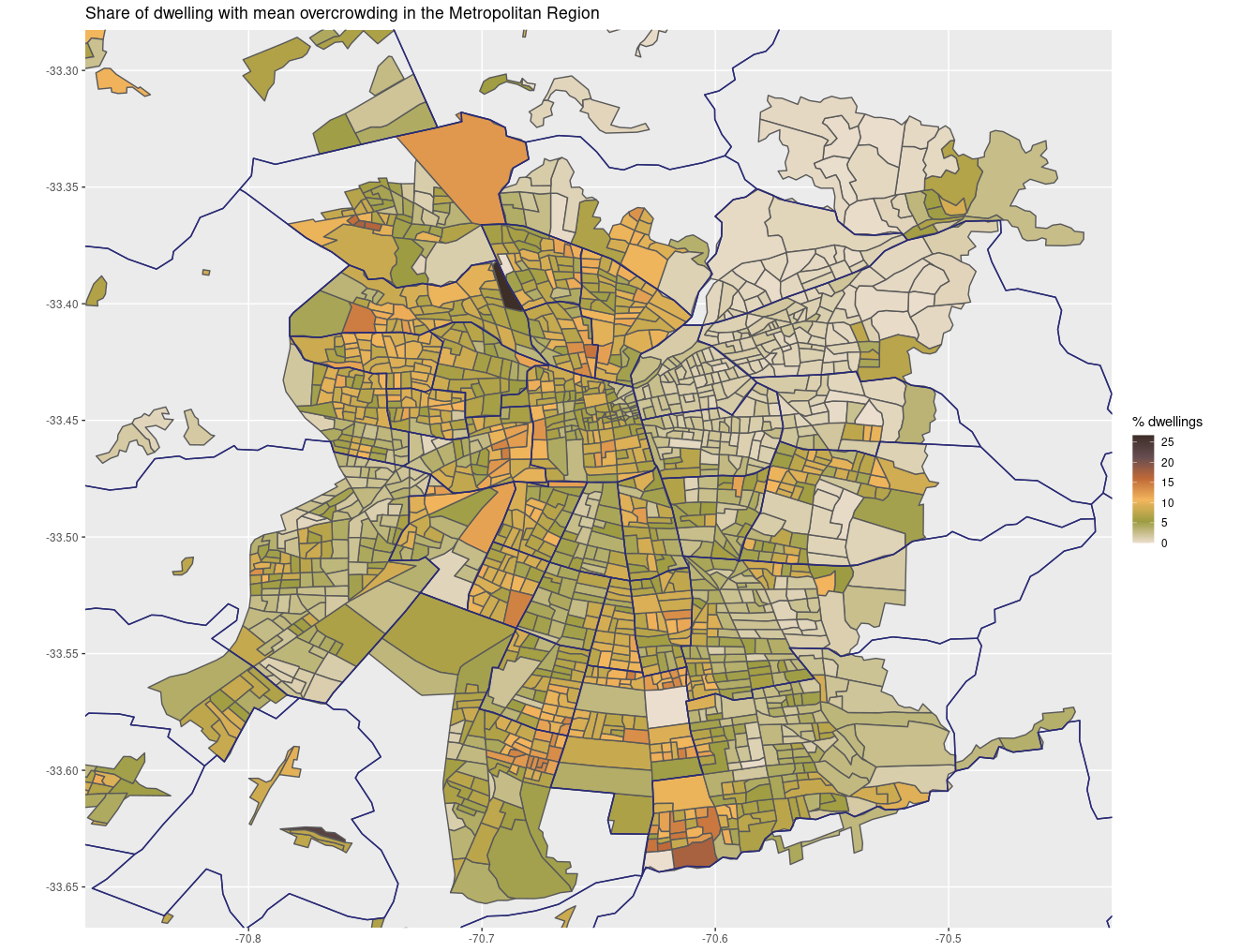
Censo2017 can be used with ggplot2 and other commonly used packages. As an example, it is possible to replicate different overcrowding maps created by both Chile’s Geographers (Geógrafas Chile) and Center For Spatial Research (Centro de Producción del Espacio) that account for overcrowding in the Metropolitan Region.
To obtain this, you need both the number of indiduals and rooms per dwellings. You can obtain the corresponding columns in the same way as the previous examples.
tbl(censo_conectar(), "variables") %>%
collect() %>%
filter(grepl("Pers", descripcion))
tabla variable descripcion tipo rango
<chr> <chr> <chr> <chr> <chr>
1 personas personan Número de la Persona integer 0 - 9999
2 viviendas cant_per Cantidad de Personas integer 0 - 9999
You need “cantidad de personas” (number of individuals) from the “viviendas” table.
tbl(censo_conectar(), "variables") %>%
collect() %>%
filter(grepl("Dorm", descripcion))
tabla variable descripcion tipo rango
<chr> <chr> <chr> <chr> <chr>
1 viviendas p04 Número de Piezas Usadas Exclusivamente Como Dormitorio integer 0 - 6
From the variables “cant_per” and “p04” you can use the methodology used by the Secretary for Social Development and Family (Ministerio de Desarrollo Social y Familia), which consists in taking the ratio of people residing in the dwelling and the number of bedrooms in the dwelling. The variable is then discretized as follows:
- No overcrowding [0,2.5)
- Mean [2.5,3.5)
- High [3.5,4.9)
- Critical [5,
Inf)
You can obtain the table with the overcrowding index for each dwelling as follows.
overcrowding <- tbl(censo_conectar(), "zonas") %>%
mutate(
region = substr(as.character(geocodigo), 1, 2),
provincia = substr(as.character(geocodigo), 1, 3),
comuna = substr(as.character(geocodigo), 1, 5)
) %>%
filter(region == 13) %>%
select(comuna, geocodigo, zonaloc_ref_id) %>%
inner_join(select(tbl(censo_conectar(), "viviendas"), zonaloc_ref_id,
vivienda_ref_id, cant_per, p04),
by = "zonaloc_ref_id") %>%
mutate(
cant_per = as.numeric(cant_per),
p04 = as.numeric(p04),
p04 = case_when(
p04 == 98 ~ NA_real_,
p04 == 99 ~ NA_real_,
TRUE ~ as.numeric(p04)
)
) %>%
filter(!is.na(p04)) %>%
mutate(
# Overcrowding index (variables at dwelling level)
ind_hacinam = case_when(
# this divides people by bedrooms (if bedrooms >= 1) and
# also for 0 bedrooms (where applies bedrooms + 1 for cases such as
# studio apartment, etc)
p04 >=1 ~ cant_per / p04,
p04 ==0 ~ cant_per / (p04 + 1)
)
) %>%
mutate(
# Hacinamiento categorias
hacinam = case_when(
ind_hacinam < 2.5 ~ "No Overcrowding",
ind_hacinam >= 2.5 & ind_hacinam < 3.5 ~ "Mean",
ind_hacinam >= 3.5 & ind_hacinam < 5 ~ "High",
ind_hacinam >= 5 ~ "Critical"
)
) %>%
collect()
To obtain the shares, you can aggregate to obtain the corresponding counts, taking into account that you don’t have to ignore the zeroes, and specially if you want to visualize the information or you’ll end up with empty areas in your map. To perform this step, you can use tidyr and janitor to obtain one column per overcrowding category.
library(tidyr)
library(janitor)
overcrowding1 <- overcrowding %>%
group_by(geocodigo, hacinam) %>%
count()
overcrowding2 <- expand_grid(
geocodigo = unique(overcrowding$geocodigo),
hacinam = c("No Overcrowding", "Mean", "High", "Critical")
)
overcrowding2 <- overcrowding2 %>%
left_join(overcrowding1) %>%
pivot_wider(names_from = "hacinam", values_from = "n") %>%
clean_names() %>%
mutate_if(is.numeric, function(x)
case_when(is.na(x) ~ 0, TRUE ~ as.numeric(x))) %>%
mutate(
total_viviendas = no_overcrowding + mean + high + critical,
prop_sin = 100 * no_overcrowding / total_viviendas,
prop_mean = 100 * mean / total_viviendas,
prop_high = 100 * high / total_viviendas,
prop_critical = 100 * critical / total_viviendas
)
overcrowding2
# # A tibble: 2,421 x 10
# geocodigo no_overcrowding mean high critical total_viviendas prop_sin prop_mean prop_high prop_critical
# <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
# 1 13101011001 1072 28 2 2 1104 97.1 2.54 0.181 0.181
# 2 13101011002 1127 57 14 7 1205 93.5 4.73 1.16 0.581
# 3 13101011003 1029 23 6 4 1062 96.9 2.17 0.565 0.377
# 4 13101011004 801 49 18 13 881 90.9 5.56 2.04 1.48
# 5 13101011005 886 49 9 5 949 93.4 5.16 0.948 0.527
# 6 13101021001 1219 107 35 16 1377 88.5 7.77 2.54 1.16
# 7 13101021002 1223 78 15 7 1323 92.4 5.90 1.13 0.529
# 8 13101021003 1173 105 34 9 1321 88.8 7.95 2.57 0.681
# 9 13101021004 1199 110 47 14 1370 87.5 8.03 3.43 1.02
# 10 13101021005 826 87 29 10 952 86.8 9.14 3.05 1.05
# # … with 2,411 more rows
Now you are ready to create a map. As an example, here’s the mean overcrowding map, the others are left as exercise.
# if (!require("colRoz")) remotes::install_github("jacintak/colRoz")
library(chilemapas)
library(colRoz)
ggplot() +
geom_sf(data = inner_join(overcrowding2, mapa_zonas),
aes(fill = prop_mean, geometry = geometry)) +
geom_sf(data = filter(mapa_comunas, codigo_region == "13"),
aes(geometry = geometry), colour = "#2A2B75", fill = NA) +
ylim(-33.65, -33.3) +
xlim(-70.85, -70.45) +
scale_fill_gradientn(colors = rev(colRoz_pal("ngadju")), name = "% dwellings") +
labs(title = "Share of dwelling with mean overcrowding in the Metropolitan Region")
🔗 Links to training and policy
Using open formats per se ease working as it reduces compatibility problems when reading data, but datasets have to include proper documentation, not just come in proper formats. For the particular case of censo2017, it makes education and research resources more equitable, as it helps any institution that runs applied statistics courses or research to conduct census statistical analysis regardless of the tools they use, and focus on a region or any group of interest, such as the indigenous population, the elderly or the people living in apartments.
The census database I provide within the package can be read in Python, Java C++, node.js and even right away from a command line, and it is important to mention that it’s multiplatform. For the case of GUI-based applied statistical analysis, censo2017 makes it very easy to export subsets to Microsoft Excel or Google Sheets, without the disadvantages of the original census format previously discussed, and even to Stata and SPSS thanks to the R packages ecosystem.
Those who, like me, write R packages can to do our contribution by creating tools that could support the countries in the region to get back on track to achieving the Sustainable Development Goals defined by the United Nations, even in spite of the recent rise of protectionism, political uncertainty and unclear attitude towards global trade regime seen in Latin America. Developing and enacting thoughtful policy is the only way to say ‘checkmate’ to underdevelopment.
🔗 rOpenSci community contribution
The help of rOpenSci and its software review was pivotal. Dedicated reviewers, María Paula Caldas, Frans van Dunné and Melina Vidoni, tested the package and suggested enhancements. Their reviews were very helpful, they gave extremely valuable advice and were really supportive of my work and the development of the package.
The interested reader shall find a complete record of all the changes made during the reviewing process, where everything is commented in Spanish, and there shall be newer rOpenSci packages in languages other than English. Since 2011, rOpenSci has been creating technical infrastructure in the form of R software tools that lower barriers to working with scientific data. I can only remember the talk by my friend and colleague Riva Quiroga, where she highlights that initiatives such as this are not just software, but tools to make the community stronger.
I’d love to see different ‘forks’ of censo2017 in the contiguous countries Peru and Bolivia, and the rest of the region. Creating the first rOpenSci package fully documented in Spanish is not just about inclusiveness, which is obviously desirable. This is also related to productivity, because in Latin America materials that are documented in English are hard to understand and therefore the tools are not adopted as one would want. And just like the infrastructure for R4DS in Spanish motivated the creation of R4DS in Portuguese, I hope that censo2017 opens the door for interesting collaborations and similar packages in different languages.
I think I do my best to contribute to initiatives such as rOpenSci because here I have found my place and discovered others who have a heartfelt wish to learn at many different things. My present contribution is making the right data, tools and best practices more discoverable while contributing to social infrastructure at the same time.
Redatam is a widely used software for disseminating population censuses. While it is free to use, it uses a closed format. ↩︎
For the period June 2018 - December 2019, the Census was available in DVD and REDATAM formats only. Now it’s available online in REDATAM, SPSS and CSV formats. ↩︎
For the case of Chile, the most aggregated division of economic activity separates production into twelve branches: Agriculture and fishing; mining; manufacturing industry; electricity, gas and water; construction; retail, hotels and restaurants; transport, communications and information; financial services; real estate; business services; personal services; public administration. For a more detailed description, you can explore the Input-Output Matrix of the Chilean economy and/or the leontief package for sectoral analysis. ↩︎
From a methodological point of view, it’s easier to count people aged 64 or more (the legal age to be considered elder), than to count retired people, as some industries allow people to retire later while others don’t, and the decision is left up to agreement between the employee and the employer. ↩︎
Filed under
Suggest an edit
Open a pull request
