Tuesday, June 6, 2023
From rOpenSci (https://ropensci.org/blog/2023/06/06/r-universe-stars-4-en/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
Meeting the Stars of the R-Universe: PEcAn, an Open Source Project to Take Care of the Planet
This post is part of a series of technotes about r-universe, a new umbrella project by rOpenSci under which we experiment with various ideas for improving publication and discovery of research software in R.
As the project evolves, we will post updates to document features and technical details.
For more information, visit the r-universe project page.
A new post of our interview series “Meeting the stars of the R-universe”. We aim to introduce the teams and people behind the development of software and packages many of us use and which are available through the R-Universe. We want to highlight and explore different teams and projects around the world, the work they do, their processes and users. Our third stop is the United States to talk with members of the PEcAn project. Be sure to watch the video at the end with excerpts from the interview.
🔗
Climate change and research in this area have diverse and complex data that demand increasingly complex analysis models. The PEcAn project works to develop this ability.
In this next interview, we will go into the science of climate change, and explore where data analysis and ecosystem modeling tools are developed. That is the main objective of the PEcAn project, where they collaboratively seek new ways to collect and synthesize data and develop accessible tools to perform these tasks in a reproducible way.
Our discussion was attended by Rob Kooper, Chris Black, Eric Scott, Michael C. Dietze, and David LeBauer. All members of the PEcAn project with the same goal: to find more and better ways to integrate the enormous amount of existing data on climate change.
David LeBauer, Michael C. Dietze, Rob Kooper, Eric Scott, and Chris Black
According to Michael C. Dietze’s own account, the project “is like a kind of computerized data modeling system. It’s a set of tools that facilitate the combination of process and data models, with a special focus on ecological models.”
In the project description, the concept of community quickly comes up. They have a large network of people distributed geographically and strategically, allowing them to reach more students involved in different parts of the process and in different projects. Thus, they can share work with many people simultaneously, have a significant number of collaborators and disseminate knowledge beyond academic boundaries because, as Rob explains, those students will continue their developments in other places where they are likely to bring their tools and data packages. In these connections and collaborative work lies much of the strength of the PEcAn Project.
An example of this practice is the project they are developing with Brooklyn National Laboratory, where they are working on NASA carbon monitoring that uses a data simulation system. In this case, there are both PhD students and Post Doctoral Researchers working on the project.
In this work structure, one of the main objectives is to become a kind of “Hacker” that solves problems in a more general sense that can then be applied in other contexts and in other areas. According to Rob, knowledge can be sustained and grow thanks to the research developed across multiple institutions including University of Illinois, Boston University, University of Arizona, University of Wisconsin and Brookhaven National Laboratory.
Working with Google Summer of Code, which has helped with developing and promoting an ecosystem of modeling tools, Chris explains that part of the success is that it is not just one university doing research but a large team of people all over the world working together. Although it takes longer, the result is used by a much wider community.
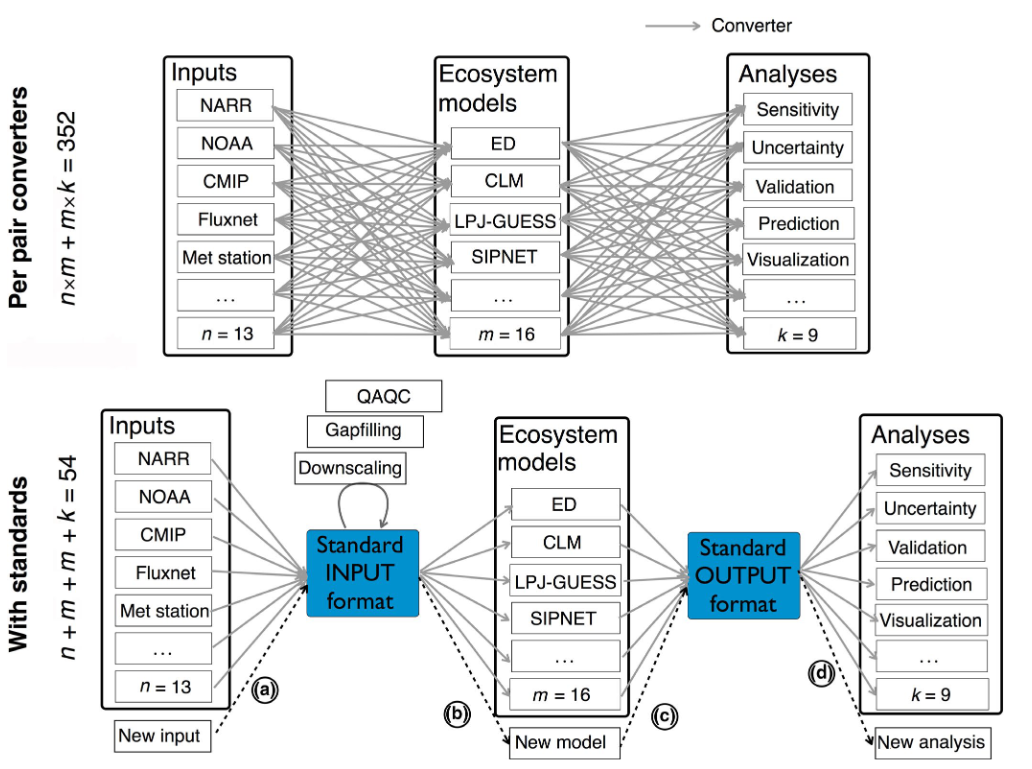
Conventional and Standards approach to modeling. PEcAn project is an example of the standards approach for modeling.
By using standards and having packages that can solve the reading, embedding and writing of all the data involved in the process, researchers don’t need to know how many different formats work, or communicate with many different research teams, in order to do this kind of work.
This allows an individual researcher to run a whole ensemble models. “Just a couple of years ago analyzing multi-models was not something that was accessible to individual researchers” Michael explains.
PEcAn packages are organized into different groups, such as basic packages, useful tools, and modules that include packages for data management and also packages to do statistical analysis on the inputs and outputs of the models.
In addition, with so many people working on the packages, errors are more likely to discovered. Although the team knows that the PEcAn project code is not bug-free, they have a better chance of finding and fixing bugs by having more eyes looking at the same thing.
In the following video, the team shares how they organize the packages in the R-Universe and the strengths of using this tool:
A digest of R package and software review news, use cases, blog posts, and events, curated monthly. Subscribe to get it in your inbox, or check the archive.