
Tuesday, June 20, 2017 From rOpenSci (https://ropensci.org/blog/2017/06/20/checkers/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
Two years ago at #runconf15, there was a great discussion about best practices for organizing R-based analysis projects that yielded a nice guidance document describing research compendia. Compendia, as we described them, were minimal products of reproducible research, using parts of R package structure to organize the inputs, analyses, and outputs of research projects.
Since then, we’ve seen more examples and models of research compendia emerge (the organization of such projects is something of an obsession for some of the community). In parallel, there’s been much progress on a number of fronts with R packages: rOpenSci’s package review process has expanded and we’ve worked out many kinks. Infrastructure for automated testing of package code has been developed and field tested. So at #runconf17, we wanted to see how much of this progress in review, testing, and automation could apply to research compendia.
It turns out there’s a lot to do here, and a lot of interest! We put up a proposal as a GitHub issue; before the unconf even began, the thread had over 50 posts and the discussion had yielded two design documents led by Hadley Wickham on research compendium organization and automated build systems. There were easily four or five projects wrapped up in the proposal.
The thread also revealed many schools of thought. As Nick put it, “The problem with opinionated analysis development is that everyone has an opinion.” We never reached consensus on basic issues like directory structure and build systems.
 Wading our way through a thorny bramble of opinions (photo: Alice Daish)
Wading our way through a thorny bramble of opinions (photo: Alice Daish)
In the face of a beast of a topic, and so many unresolved decisions, we decided to tackle a modest slice - a guide for compendium review, and a first pass at a package for automated checks of various best practices.
🔗 Reviewing a research compendium
How does one do peer review for a research compendium in the face of so much heterogeneity in types and styles of analysis? We spent the better part of our first day brainstorming everything that one might review, from the meta-topics (“Is there a clear question?”) to minutiae (“Are library() calls at the top of the script?”), and mapping these out on an ever more data-dense whiteboard:
 Nick, Jennifer, Molly and Alice discussing analysis best practices (photo: Alice Daish)
Nick, Jennifer, Molly and Alice discussing analysis best practices (photo: Alice Daish)
 The team prioritizing data analysis workflow best practice into tiers (photo: Nistara Randhawa)
The team prioritizing data analysis workflow best practice into tiers (photo: Nistara Randhawa)
 With our 7th team member, Wy T. Board (photo: Alice Daish)
With our 7th team member, Wy T. Board (photo: Alice Daish)
These review topics made their way into a Google doc which will form the basis of a review guide along the lines of rOpenSci’s package review guides. One major organizing dimension we hit upon was “Tiers” - as the number of best practices can be overwhelming, it is better to prioritize them so that users have a way of advancing through escalating levels of detail. Another was “automatability,” which is key to the other half of our work.
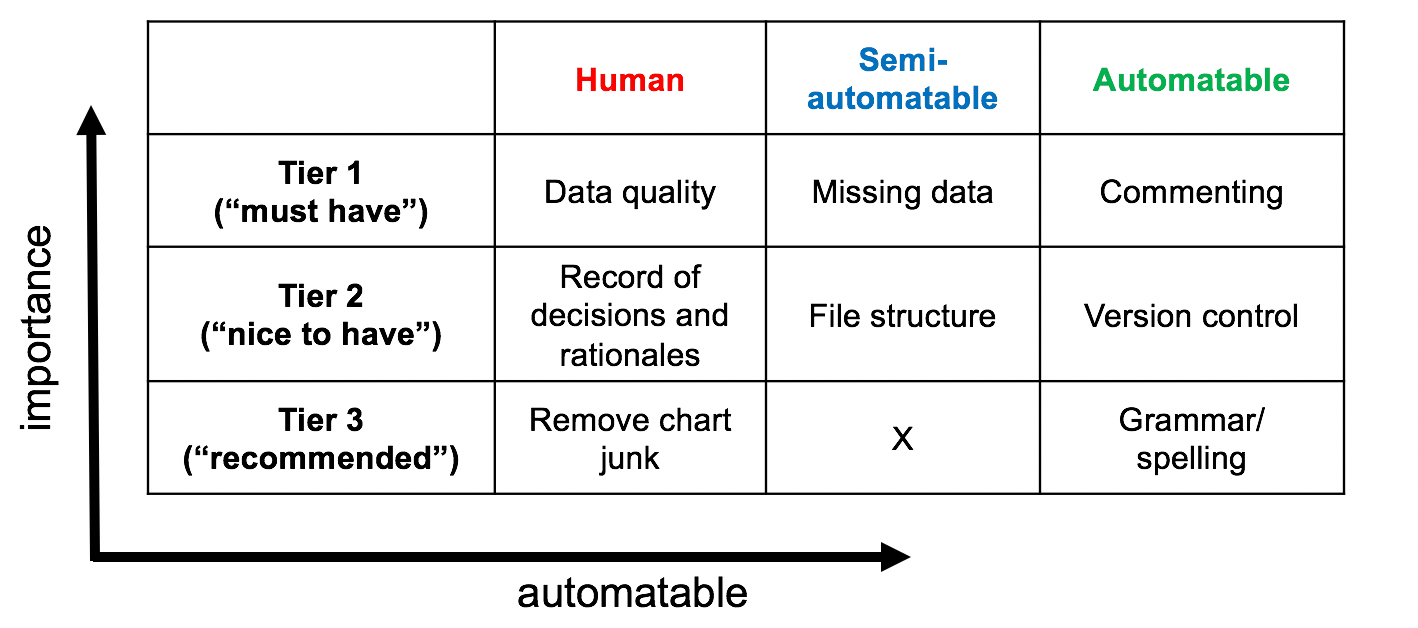
🔗 checkers: R CMD check for your data analysis
One of the lessons of the rOpenSci package review process has been that reviews work better when we let reviewers focus on the tasks that humans are best at, and find ways to automate tedious or tiny tasks. So for the second aim of our project, we built a package to run the automatable components of review and create reports for analysts and reviewers. The package, checkers, is meant to be, as Hadley coined it, “R CMD check for your data analysis.”
checkers scans the project directory and delivers advice on how to improve project code, like so:
> checkers::gp_check()
─────────────────────────────────────────────────────────────────────
It is good practice to
✖ Place your project under version control. You are using
neither git nor svn. See http://happygitwithr.com/ for more
info
✖ Use preferred packages. xml2 is preferred to XML.
──────────────────────────────────────────────────────────────────
One area we had to tackle was the need for both opinionated defaults and configurability. So we built in the ability for individuals or teams to select or define their own best practices in a shared YAML configuration file.
🔗 Stone soup development at the unconf
The review guide and checkers are works in progress, but both made great leaps forward in two days thanks to the tremendous catalyzing environment of the unconf. While our team of six only formed the morning of the first day, the pre-unconf discussion meant that many more people from the community shaped contours of the project.
Also, one of the great things about the unconf is that so many experienced developers are on hand to chip in with their areas of expertise. Hadley Wickham joined in to brainstorm some of the initial best practices to include in our guide. Later, we decided to base our checks system on Gábor Csárdi’s goodpractice, and Gábor worked with us to build a flexible extension system into that package. Jim Hester was on hand to answer questions about lintr internals, and we’ll be sending some changes upstream to that as well.
 Laura and Gábor practicing goodpractices (photo: Nistara Randhawa)
Laura and Gábor practicing goodpractices (photo: Nistara Randhawa)
 Team reviewing framework and package development examples (photo: Alice Daish)
Team reviewing framework and package development examples (photo: Alice Daish)
We’re excited about the potential for this project, and just as excited about the potential of what else we’ll make with our new friends and collaborators. Thanks to rOpenSci and everyone who made #runconf17 such a tremendously productive and fun event!
Filed under
Suggest an edit
Open a pull request
