
Tuesday, August 22, 2017 From rOpenSci (https://ropensci.org/blog/2017/08/22/visdat/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
Take a look at the data
This is a phrase that comes up when you first get a dataset.
It is also ambiguous. Does it mean to do some exploratory modelling? Or make some histograms, scatterplots, and boxplots? Is it both?
Starting down either path, you often encounter the non-trivial growing pains of working with a new dataset. The mix ups of data types - height in cm coded as a factor, categories are numerics with decimals, strings are datetimes, and somehow datetime is one long number. And let’s not forget everyone’s favourite: missing data.
These growing pains often get in the way of your basic modelling or graphical exploration. So, sometimes you can’t even start to take a look at the data, and that is frustrating.
The visdat package aims to make this preliminary part of analysis easier. It focuses on creating visualisations of whole dataframes, to make it easy and fun for you to “get a look at the data”.
Making visdat was fun, and it was easy to use. But I couldn’t help but think that maybe visdat could be more.
- I felt like the code was a little sloppy, and that it could be better.
- I wanted to know whether others found it useful.
What I needed was someone to sit down and read over it, and tell me what they thought. And hey, a publication out of this would certainly be great.
Too much to ask, perhaps? No. Turns out, not at all. This is what the rOpenSci onboarding process provides.
🔗 rOpenSci onboarding basics
Onboarding a package onto rOpenSci is an open peer review of an R package. If successful, the package is migrated to rOpenSci, with the option of putting it through an accelerated publication with JOSS.
What’s in it for the author?
- Feedback on your package
- Support from rOpenSci members
- Maintain ownership of your package
- Publicity from it being under rOpenSci
- Contribute something to rOpenSci
- Potentially a publication
What can rOpenSci do that CRAN cannot?
The rOpenSci onboarding process provides a stamp of quality on a package that you do not necessarily get when a package is on CRAN 1. Here’s what rOpenSci does that CRAN cannot:
- Assess documentation readability / usability
- Provide a code review to find weak points / points of improvement
- Determine whether a package is overlapping with another.
So I submitted visdat to the onboarding process. For me, I did this for three reasons.
- So
visdatcould become a better package - Pending acceptance, I would get a publication in JOSS
- I get to contribute back to rOpenSci
Submitting the package was actually quite easy - you go to submit an issue on the onboarding page on GitHub, and it provides a magical template for you to fill out 2, with no submission gotchas - this could be the future 3. Within 2 days of submitting the issue, I had a response from the editor, Noam Ross, and two reviewers assigned, Mara Averick, and Sean Hughes.
I submitted visdat and waited, somewhat apprehensively. What would the reviewers think?
In fact, Mara Averick wrote a post: “So you (don’t) think you can review a package” about her experience evaluating visdat as a first-time reviewer.
🔗 Getting feedback
🔗 Unexpected extras from the review
Even before the review started officially, I got some great concrete feedback from Noam Ross, the editor for the visdat submission.
- Noam used the goodpractice package, to identify bad code patterns and other places to immediately improve upon in a concrete way. This resulted in me:
- Fixing error prone code such as using
1:length(...), or1:nrow(...) - Improving testing using the visualisation testing software
vdiffr) - Reducing long code lines to improve readability
- Defining global variables to avoid a NOTE (“no visible binding for global variable”)
- Fixing error prone code such as using
So before the review even started, visdat is in better shape, with 99% test coverage, and clearance from goodpractice.
🔗 The feedback from reviewers
I received prompt replies from the reviewers, and I got to hear really nice things like “I think visdat is a very worthwhile project and have already started using it in my own work.”, and “Having now put it to use in a few of my own projects, I can confidently say that it is an incredibly useful early step in the data analysis workflow. vis_miss(), in particular, is helpful for scoping the task at hand …”. In addition to these nice things, there was also great critical feedback from Sean and Mara.
A common thread in both reviews was that the way I initially had visdat set up was to have the first row of the dataset at the bottom left, and the variable names at the bottom. However, this doesn’t reflect what a dataframe typically looks like - with the names of the variables at the top, and the first row also at the top. There was also suggestions to add the percentage of missing data in each column.
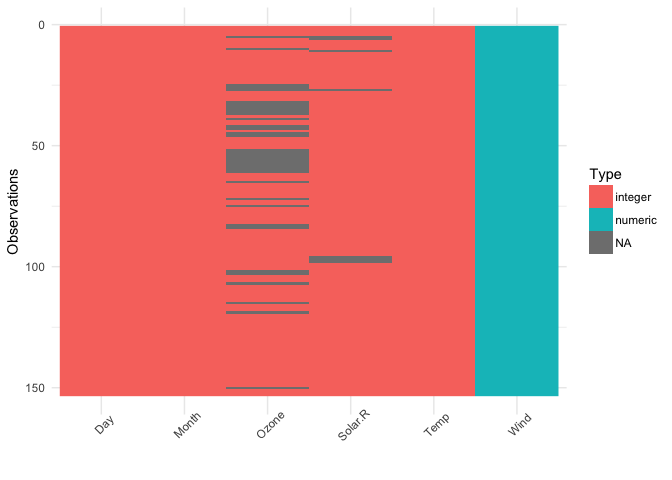
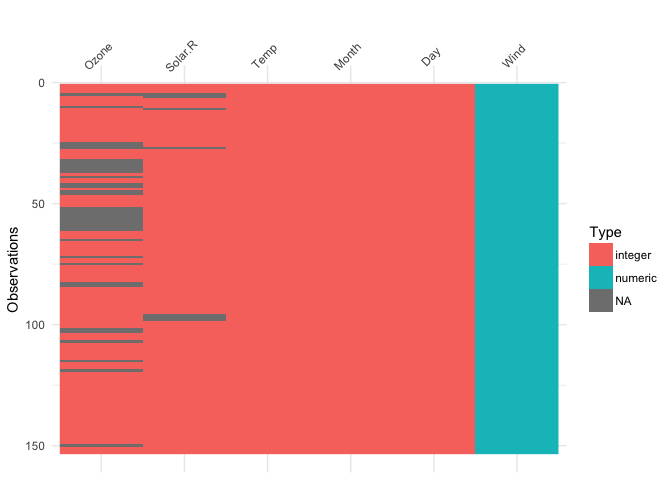
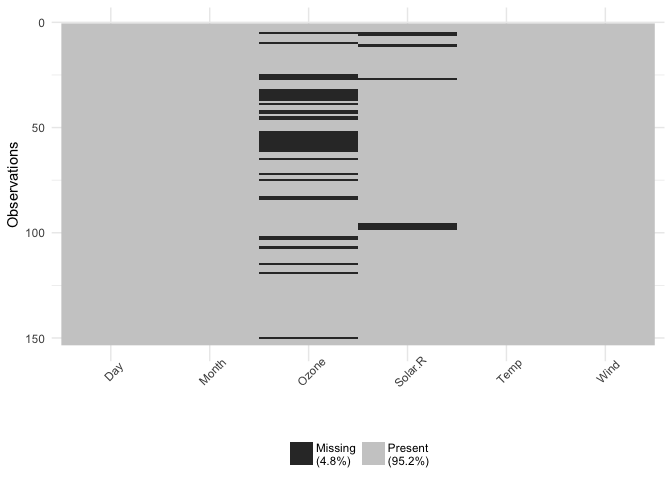
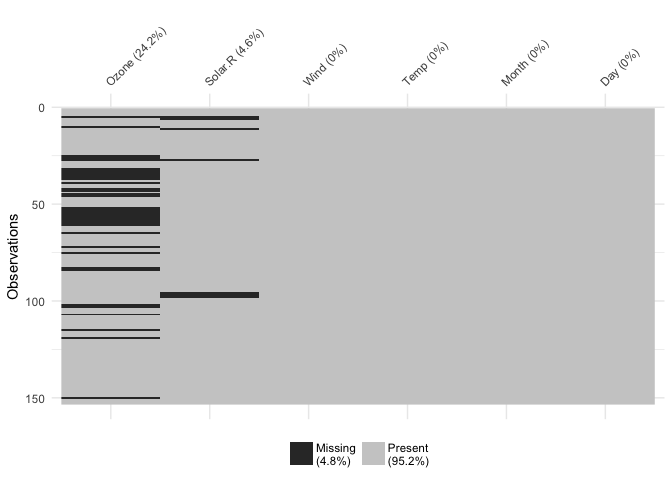
Changing this makes the plots make a lot more sense, and read better.
Mara made me aware of the warning and error messages that I had let crop up in the package. This was something I had grown to accept - the plot worked, right? But Mara pointed out that from a user perspective, seeing these warnings and messages can be a negative experience for the user, and something that might stop them from using it - how do they know if their plot is accurate with all these warnings? Are they using it wrong?
Sean gave practical advice on reducing code duplication, explaining how to write general construction method to prepare the data for the plots. Sean also explained how to write C++ code to improve the speed of vis_guess().
From both reviewers I got nitty gritty feedback about my writing - places where documentation that was just a bunch of notes I made, or where I had reversed the order of a statement.
🔗 What did I think?
I think that getting feedback in general on your own work can be a bit hard to take sometimes. We get attached to our ideas, we’ve seen them grow from little thought bubbles all the way to “all growed up” R packages. I was apprehensive about getting feedback on visdat. But the feedback process from rOpenSci was, as Tina Turner put it, “simply the best”.
Boiling down the onboarding review process down to a few key points, I would say it is transparent, friendly, and thorough.
Having the entire review process on GitHub means that everyone is accountable for what they say, and means that you can track exactly what everyone said about it in one place. No email chain hell with (mis)attached documents, accidental reply-alls or single replies. The whole internet is cc’d in on this discussion.
Being an rOpenSci initiative, the process is incredibly friendly and respectful of everyone involved. Comments are upbeat, but are also, importantly thorough, providing constructive feedback.
🔗
So what does visdat look like?
library(visdat)
vis_dat(airquality)
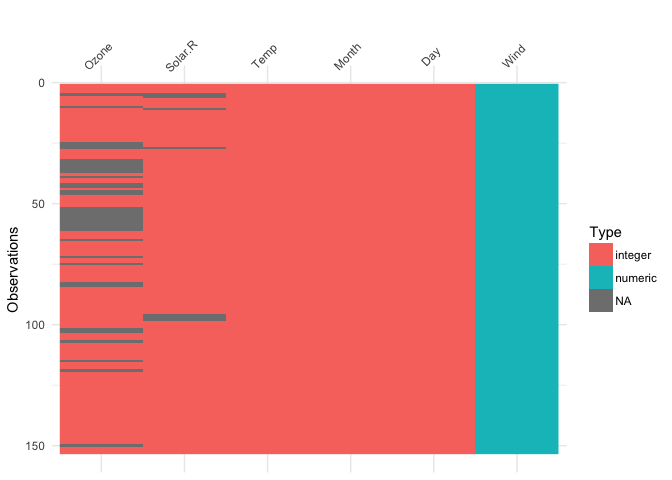
This shows us a visual analogue of our data, the variable names are shown on the top, and the class of each variable is shown, along with where missing data.
You can focus in on missing data with vis_miss()
vis_miss(airquality)
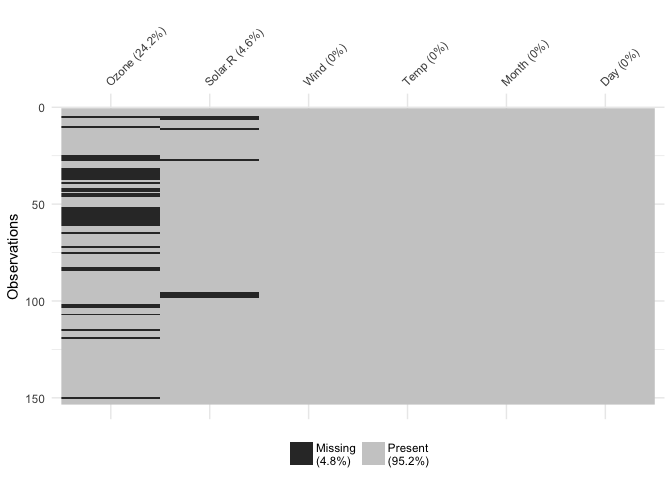
This shows only missing and present information in the data. In addition to vis_dat() it shows the percentage of missing data for each variable and also the overall amount of missing data. vis_miss() will also indicate when a dataset has no missing data at all, or a very small percentage.
🔗
The future of visdat
There are some really exciting changes coming up for visdat. The first is making a plotly version of all of the figures that provides useful tooltips and interactivity. The second and third changes to bring in later down the track are to include the idea of visualising expectations, where the user can search their data for particular things, such as particular characters like “~” or values like -99, or -0, or conditions “x > 101”, and visualise them. Another final idea is to make it easy to visually compare two dataframes of differing size. We also want to work on providing consistent palettes for particular datatypes. For example, character, numerics, integers, and datetime would all have different (and consistently different) colours.
I am very interested to hear how people use visdat in their work, so if you have suggestions or feedback I would love to hear from you! The best way to leave feedback is by filing an issue, or perhaps sending me an email at nicholas [dot] tierney [at] gmail [dot] com.
🔗 The future of your R package?
If you have an R package you should give some serious thought about submitting it to the rOpenSci through their onboarding process. There are very clear guidelines on their onboarding GitHub page. If you aren’t sure about package fit, you can submit a pre-submission enquiry - the editors are nice and friendly, and a positive experience awaits you!
CRAN is an essential part of what makes the r-project successful and certainly without CRAN R simply would not be the language that it is today. The tasks provided by the rOpenSci onboarding require human hours, and there just isn’t enough spare time and energy amongst CRAN managers. ↩︎
Never used GitHub? Don’t worry, creating an account is easy, and the template is all there for you. You provide very straightforward information, and it’s all there at once. ↩︎
With some journals, the submission process means you aren’t always clear what information you need ahead of time. Gotchas include things like “what is the residential address of every co-author”, or getting everyone to sign a copyright notice. ↩︎
Filed under
Suggest an edit
Open a pull request
