
All posts (Page 100 of 129)
Take a look at the data
This is a phrase that comes up when you first get a dataset.
It is also ambiguous. Does it mean to do some exploratory modelling? Or make some histograms, scatterplots, and boxplots? Is it both?
Starting down either path, you often encounter the non-trivial growing pains of working with a new dataset. The mix ups of data types - height in cm coded as a factor, categories are numerics with decimals, strings are datetimes, and somehow datetime is one long number. And let’s not forget everyone’s favourite: missing data.
...Last week we released an update of the tesseract package to CRAN. This package provides R bindings to Google’s OCR library Tesseract.
install.packages("tesseract")
The new version ships with the latest libtesseract 3.05.01 on Windows and MacOS. Furthermore it includes enhancements for managing language data and using tesseract together with the magick package.
🔗
Installing Language Data
The new version has several improvements for installing additional language data. On Windows and MacOS you use the tesseract_download() function to install additional languages:
Last week, version 1.0 of the magick package appeared on CRAN: an ambitious effort to modernize and simplify high quality image processing in R. This R package builds upon the Magick++ STL which exposes a powerful C++ API to the famous ImageMagick library.
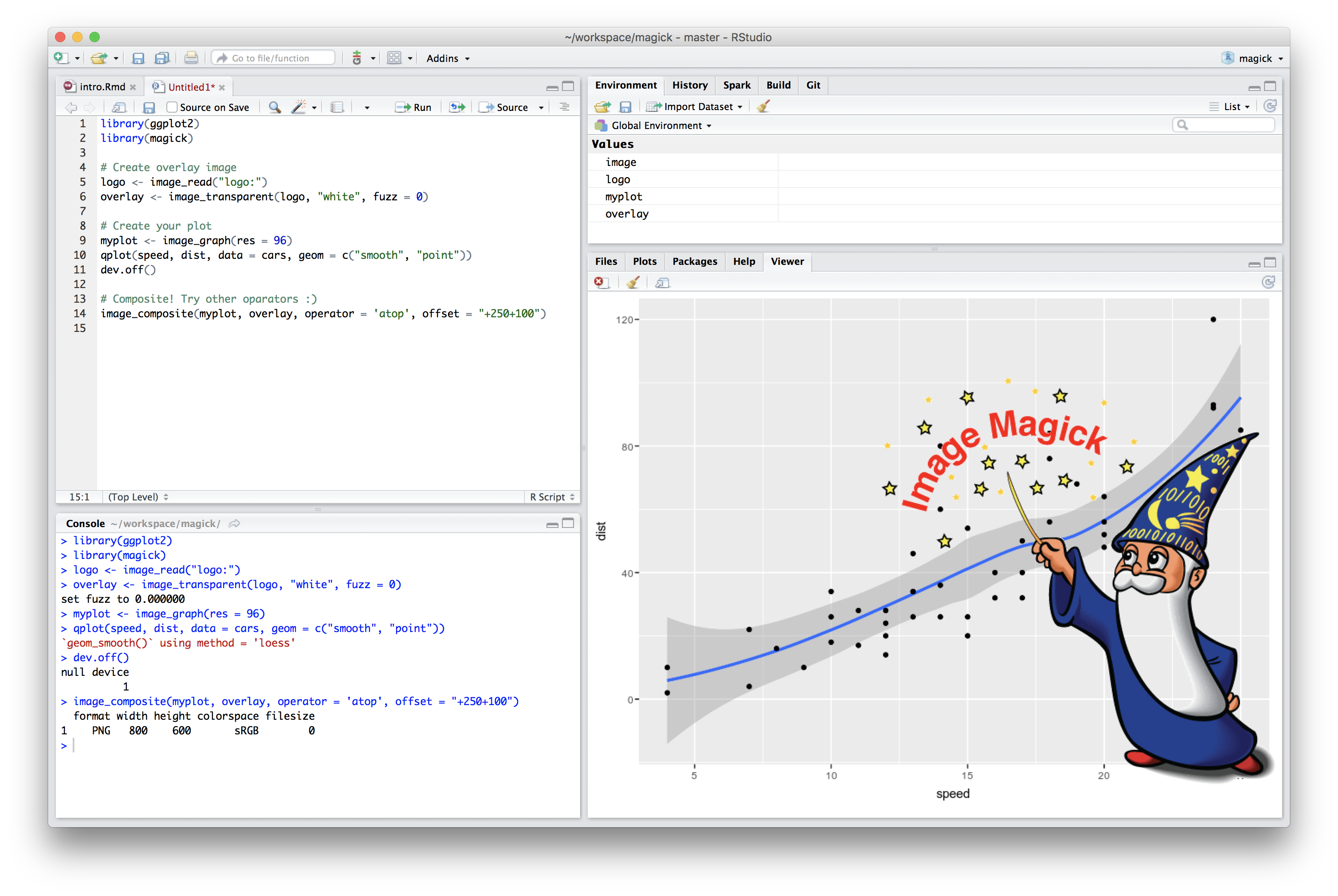
The best place to start learning about magick is the vignette which gives a brief overview of the overwhelming amount of functionality in this package.
🔗
Towards Release 1.0
Last year around this time rOpenSci announced the first release of the magick package: a new powerful toolkit for image reading, writing, converting, editing, transformation, annotation, and animation in R. Since the initial release there have been several updates with additional functionality, and many useRs have started to discover the power of this package to take visualization in R to the next level.
...You can find members of the rOpenSci team at various meetings and workshops around the world. Come say ‘hi’, learn about how our packages can enable your research, or about our onboarding process for contributing new packages, discuss software sustainability or tell us how we can help you do open and reproducible research....
Since June, we have been highlighting the many projects that emerged from this year’s rOpenSci Unconf. These projects start many weeks before unconf participants gather in-person. Each year, we ask participants to propose and discuss project ideas ahead of time in a GitHub repo. This serves to get creative juices flowing as well as help people get to know each other a bit through discussion.
This year wasn’t just our biggest unconf ever, it was the biggest in terms of proposed ideas! We had more proposals than participants, so we had a great pool to draw from when we got down to work in L.A. Yet many good ideas were left on the cutting room floor. Here we highlight some of those ideas we didn’t quite get to. Many have lots of potential and we hope the R and rOpenSci communities take them up!
...



