martes, 6 de junio de 2023
From rOpenSci (https://ropensci.org/es/blog/2023/06/06/r-universe-stars-4-es/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
Conociendo a las estrellas del Universo R: PEcAn, un proyecto de código abierto para cuidar el planeta
Este post es parte de una serie de artículos sobre r-universe, un nuevo proyecto marco de rOpenSci bajo el cual experimentamos con varias ideas para mejorar la publicación y el descubrimiento de software de investigación en R. A medida que el proyecto evolucione, publicaremos actualizaciones para documentar características y detalles técnicos. Para más información, visita la página del proyecto r-universe.
Un nuevo artículo de nuestra serie de entrevistas “Conociendo a las estrellas del universo R”. Nuestro objetivo es presentar a los equipos y personas que están detrás del desarrollo de software y paquetes que utilizamos y que están disponibles a través del R-universe. Queremos destacar y explorar diferentes equipos y proyectos de todo el mundo, el trabajo que realizan, sus procesos y usuarios. Nuestra tercera parada es Estados Unidos para hablar con representantes del proyecto PEcAn. No te olvides de mirar el video al final del artículo con extractos de la entrevista.
🔗
El cambio climático y la investigación en este ámbito cuentan con datos diversos y complejos que exigen modelos de análisis cada vez más complejos. El proyecto PEcAn trabaja para desarrollar esta capacidad.
En este nuevo encuentro vamos a adentrarnos en la ciencia del cambio climático y exploraar el desarrollo de herramientas de análisis de datos y modelización de ecosistemas. Ese es el principal objetivo del proyecto PEcAn donde de manera colaborativa buscan nuevas formas de recopilación y sintetización de datos y desarrollan herramientas accesibles para realizar estas tareas de forma reproducible.
De la charla participaron Rob Kooper, Chris Black, Eric Scott, Michael C. Dietze y David LeBauer, todos integrantes del proyecto PEcAn con un mismo objetivo: encontrar más y mejores formas de integrar la enorme cantidad de datos existentes relacionados al cambio climático.
David LeBauer, Michael C. Dietze, Rob Kooper, Eric Scott y Chris Black
Según Michael C. Dietze el proyecto “es como una especie de sistema informático de modelos de datos. Se trata de un conjunto de herramientas que facilitan la combinación de modelos de procesos y datos, con especial atención en los modelos ecológicos”.
En la descripción del proyecto, rápidamente aparece el concepto de comunidad. Cuentan con una gran red de personas distribuidas geográfica y estratégicamente que les permite llegar a más estudiantes que participan en distintas partes del proceso y en distintos proyectos. Así, pueden compartir el trabajo con muchas personas al mismo tiempo, contar con un número importante de personas que colaboran y difundir conocimiento más allá de los límites académicos porque, como explica Rob, esos estudiantes seguirán sus desarrollos en otros lugares donde es probable que lleven sus herramientas y paquetes de datos. En esas conexiones y en ese trabajo colaborativo radica gran parte de la fortaleza del proyecto PEcAn.
Un ejemplo de esta práctica es el proyecto que desarrollan con el Laboratorio Nacional de Brooklyn donde trabajan en el monitoreo de carbono de la NASA que utiliza un sistema de simulación de datos. En este caso hay tanto estudiantes de doctorado como investigadores pos doctorales trabajando en el proyecto.
En esta estructura de trabajo, uno de los objetivos principales es transformarse en una especie de “Hacker” que resuelvan problemas en un sentido más general que luego puedan ser aplicados en otros contextos y en otras áreas. Según Rob ese conocimiento puede sostenerse y crecer gracias a las investigaciones que se desarrollan en múltiples instituciones como la Universidad de Illinois, la Universidad de Boston, la Universidad de Arizona, la Universidad de Wisconsin y el Laboratorio Nacional de Brookhaven.
EL trabajo con Google Summer of Code, el cual ha ayudado con el desarrollo y promoción de herramientas de modelización de ecosistemas, Chris explica que parte del éxito es que no sólo se trata de una universidad realizando una investigación sino que es un gran equipo de gente, a lo largo de todo el mundo trabajando colavorativamente; y aunque lleva más tiempo, el resultado es utilizado por una comunidad mucho más amplia.
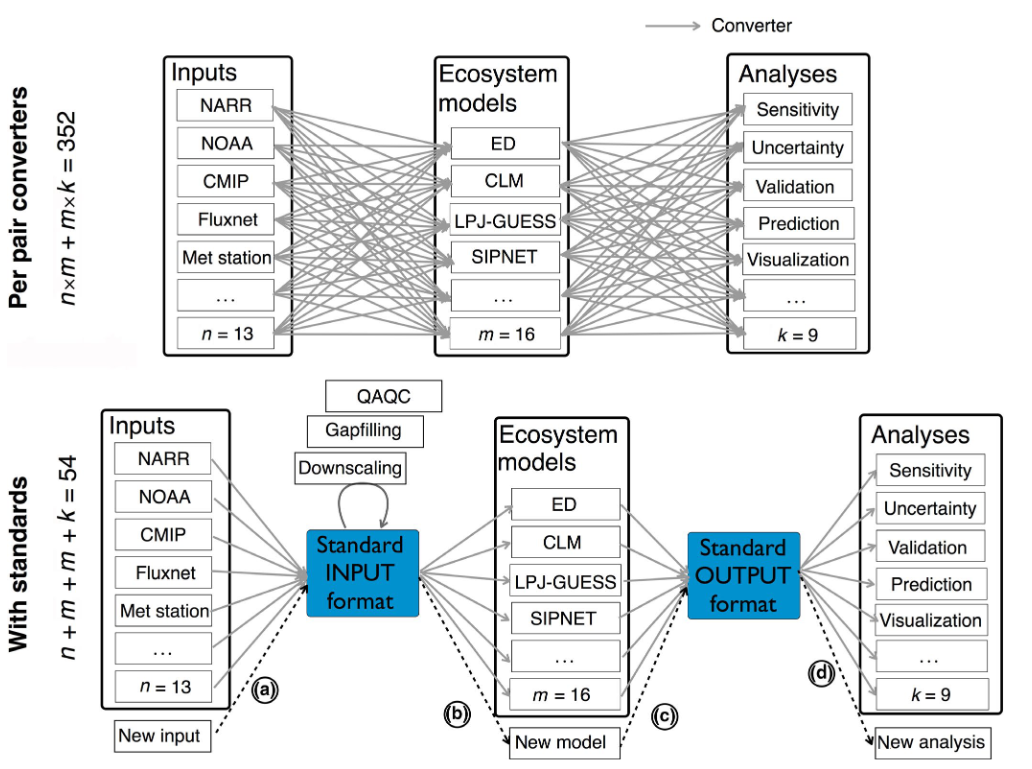
Enfoque convencional y enfoque con estándares de la modelización. El proyecto PEcAn es un ejemplo del enfoque con estándares para la modelización.
Al utilizar estándares y disponer de paquetes que pueden resolver la lectura, integración y escritura de todos los datos implicados en el proceso, quienes investigan no necesitan saber cómo funcionan muchos formatos diferentes, ni comunicarse con muchos equipos de investigación distintos, para realizar este tipo de trabajo.
Esto permite a un investigador o investigadora individual ejecutar un conjunto completo de modelos. “Hace sólo un par de años, analizar modelos múltiples no era algo accesible para los investigadores individuales”, explica Michael.
Los paquetes de PEcAn están organizados en distintos grupos, como los paquetes básicos, herramientas útiles y los módulos que incluyen paquetes para la gestión de datos y también paquetes para hacer análisis estadísticos sobre las entradas y salidas de los modelos.
Uno de los puntos más importantes de poder tener todos los paquetes de manera ordenada en el Universo R es poder simplificar el trabajo de los investigadores e investigadoras. Tener un acceso sencillo y organizado a estos modelos les ahorra años de trabajo y de recursos.
Además, con tanta gente trabajando en los paquetes, es más probable que se descubran errores. Aunque el equipo sabe que el código del proyecto PEcAn no está libre de errores, tienen más posibilidades de encontrarlos y corregirlos al tener más ojos mirando lo mismo.
En el siguiente video, el equipo muestra y cuenta cómo organizan los paquetes en el Universo R y cuáles son las fortalezas de esta herramienta:
Un compendio de noticias mensuales sobre paquetes R y revisión de software, casos de uso, artículos de blog y eventos. Suscríbete para recibirlo en tu bandeja de entrada, o consulta el archivo.