
mardi 26 septembre 2023 From rOpenSci (https://ropensci.org/fr/blog/2023/09/26/comment_traduire_un_billet_de_blog_hugo_avec_babeldown/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
Dans le cadre de notre projet d’édition multilingue et avec un financement du R Consortium nous avons travaillé sur le paquet R babeldown pour la traduction de contenu Markdown à l’aide de l’API DeepL. Dans cette note technique, nous allons montrer comment on peut utiliser babeldown pour traduire un article de blog Hugo !
🔗 Motivation
Traduire un article de blog en Markdown depuis la console R est non seulement plus confortable (quand on a déjà écrit ledit article de blog en R), mais aussi moins frustrant. Avec babeldown, comparé au copier-coller du contenu d’un billet de blog dans un quelconque service de traduction, la syntaxe Markdown ne sera pas cassée1, et les morceaux de code ne seront pas traduits. Cela fonctionne, car en pratique, babeldown utilise tinkr pour produire du XML qu’il envoie ensuite à l’API DeepL, en signalant certaines balises comme ne devant pas être traduites. Il convertit ensuite le XML traduit par DeepL en Markdown.
Comme on peut s’en douter, ce contenu traduit automatiquement n’est pas encore parfait ! Il faudra encore le travail d’un ou deux humains pour réviser et modifier la traduction. Pourquoi ne pas demander aux humains de traduire l’article à partir de zéro ? Nous avons observé que l’édition d’une traduction automatique est plus rapide que la traduction de l’ensemble du billet, et qu’elle libère de l’espace mental pour se concentrer sur la mise en œuvre de règles de traduction telles que la formulation non sexiste.
🔗 Configuration
🔗 Pré-requis sur le site Hugo
babeldown::deepl_translate_hugo() suppose que le site web Hugo utilise
- “leaf bundles” (chaque post dans un dossier,
content/path-to-leaf-bundle/index.md) ; - le multilinguisme, de sorte qu’un message en espagnol se retrouve dans par exemple)
content/path-to-leaf-bundle/index.es.md.
babeldown pourrait être étendu à d’autres configurations multilingues Hugo. Si vous souhaitez utiliser babeldown avec une configuration différente, ouvrez une “issue” dans le dépôt de babeldown!
À noter, babeldown ne pourra pas déterminer la langue par défaut du site web2 donc même si la langue par défaut du site web est l’anglais, babeldown placera une traduction anglaise dans un fichier appelé “.en.md” et non “.md”. Hugo reconnaîtra tout de même le nouveau fichier (du moins dans notre configuration).
🔗 Pré-requis DeepL
Il faut d’abord vérifier que les langues source et cible souhaitées sont prises en charge par l’API DeepL !
On peut se référer à la documentation des paramètres de l’API source_lang et target_lang pour une liste complète.
Une fois sûr·e qu’on peut profiter de l’API DeepL, il faut créer un compte pour l’API du service de traduction DeepL. Même l’obtention d’un compte gratuit nécessite l’enregistrement d’un moyen de paiement auprès d’eux.
🔗 Pré-requis R
Commençons par installer babeldown à partir de l’univers R de rOpenSci :
install.packages('babeldown', repos = c('https://ropensci.r-universe.dev', 'https://cloud.r-project.org'))
Ensuite, dans chaque session R, on définit sa clé API DeepL via la variable d’environnement DEEPL_API_KEY.
On peut l’enregistrer une fois pour toutes avec le paquet keyring et la récupérer dans les scripts comme suit :
Sys.setenv(DEEPL_API_KEY = keyring::key_get("deepl"))
Enfin, l’URL de l’API DeepL dépend de votre plan API. babeldown utilise par défaut l’URL d’API gratuite DeepL. Quand on utilise un plan Pro, on doit définir l’URL de l’API dans chaque session/script R via
Sys.setenv("DEEPL_API_URL" = "https://api.deepl.com")
🔗 Traduction !
On pourrait exécuter le code ci-dessous
babeldown::deepl_translate_hugo(
post_path = <path-to-post>,
source_lang = "EN",
target_lang = "ES",
formality = "less" # that's how we roll here!
)
mais nous recommandons d’en faire un peu plus pour de meilleurs résultats.
🔗 Traduction à l’aide d’un flux de travail Git/GitHub
Quand on utilise le contrôle de version, avoir la traduction sous forme de diff est très pratique !
🔗 Premièrement : En mots et en images
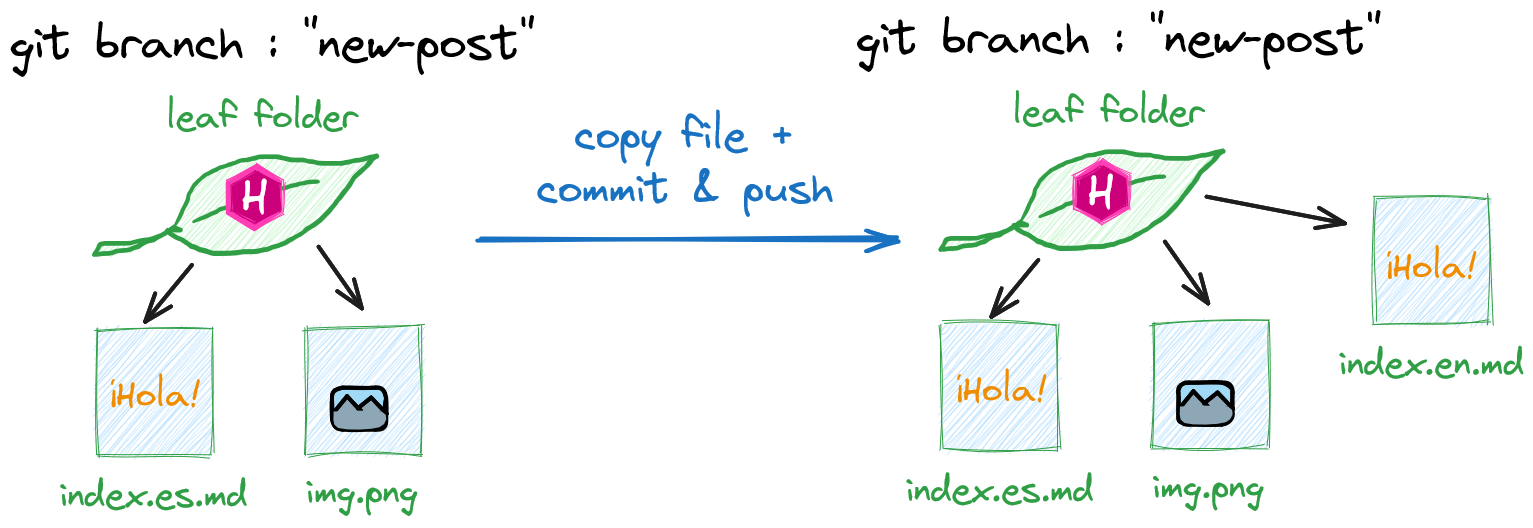
- Dans la branche de l’article à traduire (appelons-la “new-post”), on crée un fichier pour “garder la place”, en enregistrant l’article de blog original (
index.es.md) sous le nom de l’article cible (index.en.md) et en faisait un Git commit et un Git push.
- Ensuite on crée une nouvelle branche, “auto-translate” par exemple.
- Puis on exécute
babeldown::deepl_translate_hugo()avecforce = TRUE.
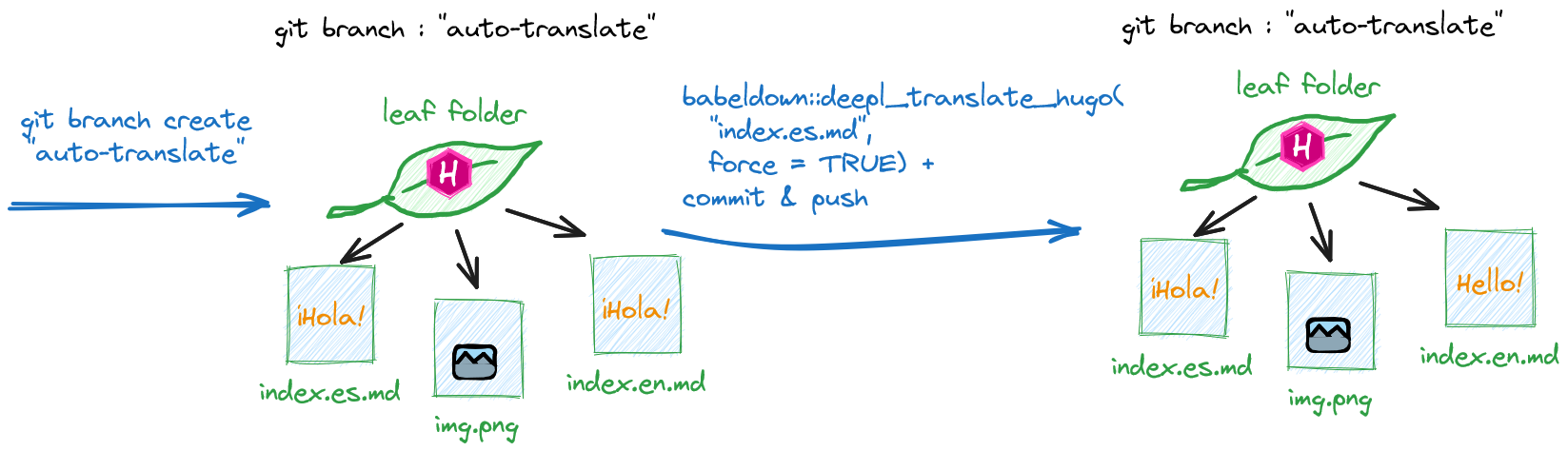
- Git commit et Git push le résultat.
- On ouvre alors une PR à partir de la page “auto-translate” à la branche “new-post”. La seule différence entre les deux branches est la traduction automatique du billet. La Git diff pour l’article de blog cible sera la différence entre la langue source et la langue cible ! En ayant la bonne habitude de commencer une nouvelle ligne après chaque phrase / partie de phrase, c’est encore mieux.

- Les traducteur·rice·s humain·e·s peuvent alors ouvrir une deuxième PR à la branche de traduction avec leurs modifications ! Ou il·elle·s peuvent ajouter leurs modifications en tant que suggestions de PR.
🔗 Encore une fois : En code
Reprenons l’exercice, mais avec des exemples de code. Ici, nous utiliserons fs et gert (mais à chacun·e ses outils favoris !), et nous supposerons que le répertoire courant est la racine du dossier du site Web, et aussi la racine du dépôt Git.
- Dans la branche post, (encore une fois, appelons-la “new-post”), enregistrer l’article de blog original (
index.es.md) sous le nom de l’article cible (index.en.md) et Git commit et Git push.
fs::file_copy(
file.path("content", "blog", "2023-10-01-r-universe-interviews", "index.es.md"),
file.path("content", "blog", "2023-10-01-r-universe-interviews", "index.en.md")
)
gert::git_add(file.path("content", "blog", "2023-10-01-r-universe-interviews", "index.en.md"))
gert::git_commit("Add translation placeholder")
gert::git_push()
- Créer une nouvelle branche, “translation-tech-note” par exemple.
gert::git_branch_create("translation-tech-note")
- Exécuter
babeldown::deepl_translate_hugo()avecforce = TRUE.
babeldown::deepl_translate_hugo(
post_path = file.path("content", "blog", "2023-10-01-r-universe-interviews", "index.es.md"),
force = TRUE,
yaml_fields = c("title", "description", "tags"),
source_lang = "ES",
target_lang = "EN-US"
)
On peut aussi omettre le post_path si on exécute le code à partir de l’IDE RStudio et si le fichier ouvert et focalisé (celui que l’on voit au-dessus de la console) est le billet à traduire.
babeldown::deepl_translate_hugo(
force = TRUE,
yaml_fields = c("title", "description", "tags"),
source_lang = "ES",
target_lang = "EN-US"
)
- Git commit et Git push le résultat avec le code ci-dessous.
gert::git_add(file.path("content", "blog", "2023-10-01-r-universe-interviews", "index.en.md"))
gert::git_commit("Add translation")
gert::git_push()
Ouvrir une PR à partir de la page “translation-tech-note” à la branche “new-post”. La seule différence entre les deux branches est la traduction automatique de
"content/blog/2023-10-01-r-universe-interviews/index.en.md".Les traducteur·rice·s humains peuvent alors a ouvrir une deuxième PR à la branche de traduction avec leurs modifications ! Ou il·elle·s peuvent ajouter leurs modifications en tant que suggestions de RP.
🔗 Résumé des branches et des PR
Au final, il devrait y avoir deux ou trois branches :
- branche A avec un article de blog en espagnol et un article de blog de remplacement pour l’anglais (avec un contenu espagnol) – PR vers la branche défaut (main) ;
- branche B avec un article de blog traduit automatiquement en anglais – PR vers la branche A ;
- Optionnellement, branche C avec la traduction automatique en anglais de l’article de blog éditée par un humain – PR vers la branche B. Si la branche C n’existe pas, les éditions par un humain sont faites en tant que suggestions de révision PR dans le PR de B à A.
Les PR sont fusionnées dans cet ordre :
- PR vers la branche B ;
- PR vers la branche A ;
- PR vers la branche principale.
🔗 Exemple réel
- PR ajoutant un article au blog rOpenSci. Il s’agit d’un PR du blog rOpenSci “r-univers-interviews” à la branche “main” (par défaut) ;
- PR ajoutant la traduction automatique. Il s’agit d’un PR vers la branche “r-universe-interviews” .
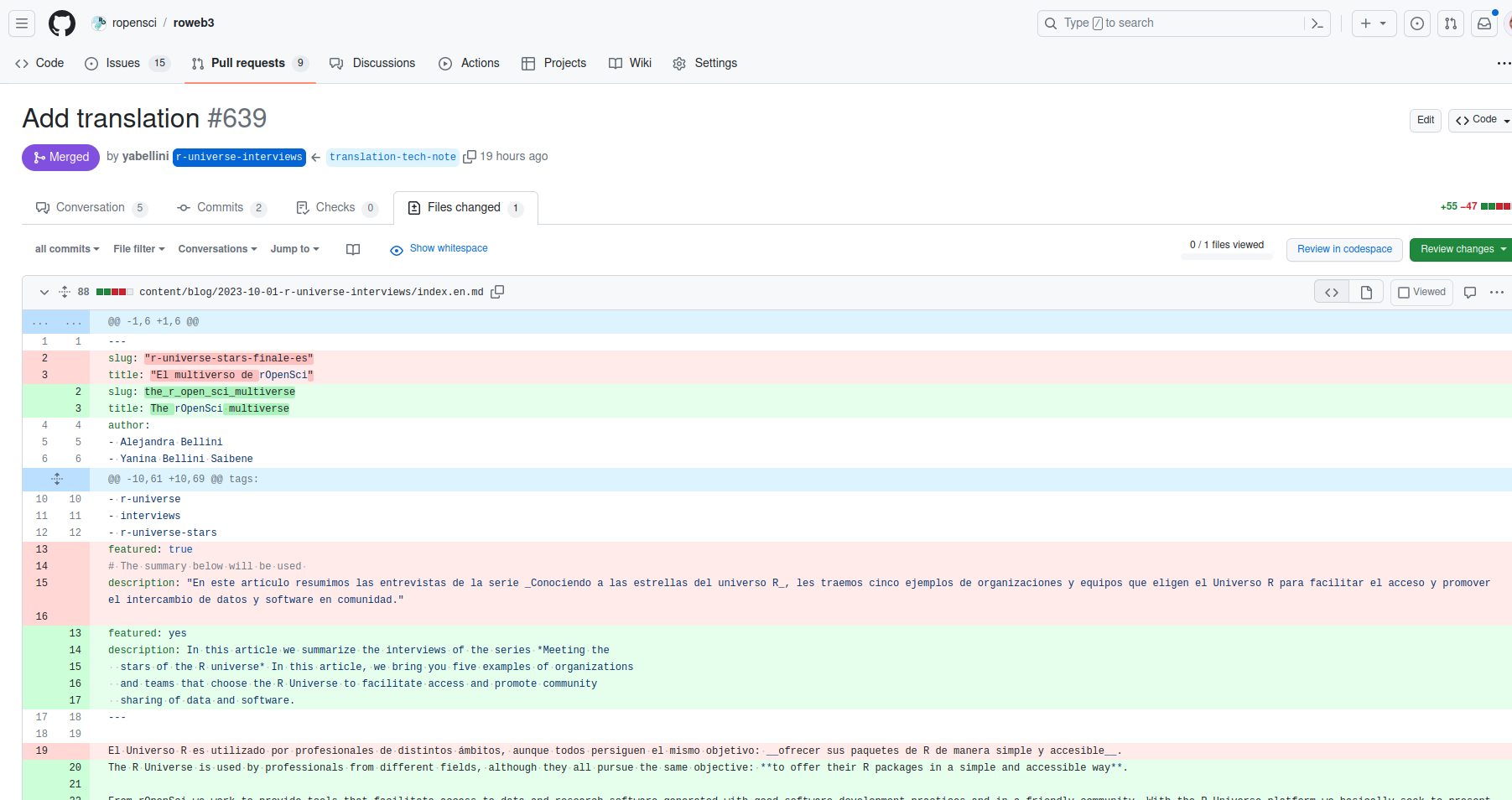
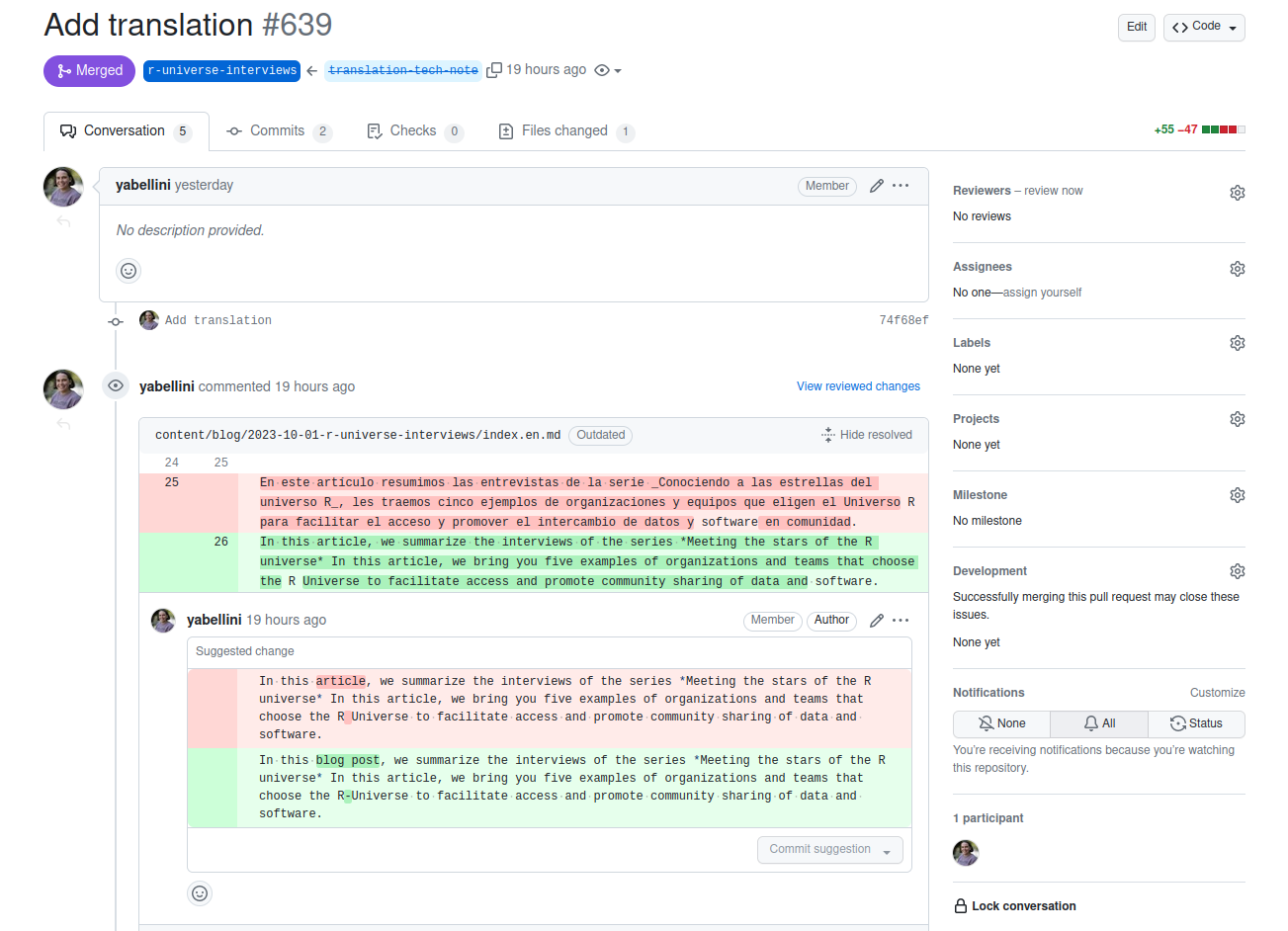
Yanina a peaufiné la traduction automatique en suggérant des changements sur la PR, puis en les acceptant.
🔗 Champs YAML
Par défaut, babeldown traduit les champs YAML “title” et “description”.
S’il y a du texte dans d’autres champs, il faut utiliser l’argument yaml_fields de babeldown::deepl_translate_hugo().
Si babeldown traduit le titre, il met à jour le slug.
🔗 Glossaire
Imaginons avoir quelques préférences pour certains mots – quelque chose que l’on accumule au fil du temps.
readr::read_csv(
system.file("example-es-en.csv", package = "babeldown"),
show_col_types = FALSE
)
## # A tibble: 2 × 2
## Spanish English
## <chr> <chr>
## 1 paquete package
## 2 repositorio repository
On peut enregistrer ces traductions préférées dans un glossaire sur notre compte DeepL.
deepl_upsert_glossary(
<path-to-csv-file>,
glossary_name = "rstats-glosario",
target_lang = "Spanish",
source_lang = "English"
)
On utilisera exactement le même code pour mettre à jour le glossaire, d’où le nom “upsert” de la fonction. Il faut un glossaire par paire langue source / langue cible : le glossaire anglais-espagnol ne peut pas être utilisé pour l’espagnol vers l’anglais par exemple.
Dans l’appel babeldown::deepl_translate_hugo() on utilise alors le nom du glossaire (ici “rstats-glosario”) pour la paire de langues source et cible. glossary argument.
🔗 Formalité
deepl_translate_hugo() a un argument formality.
Or, l’API DeepL ne prend en charge que certaines langues, comme l’explique la documentation du paramètre formality de l’API:
Définit si le texte traduit doit pencher vers un langage formel ou informel. Cette fonction ne fonctionne actuellement que pour les langues cibles DE (allemand), FR (français), IT (italien), ES (espagnol), NL (néerlandais), PL (polonais), PT-BR et PT-PT (portugais), JA (japonais) et RU (russe). (…) Le réglage de ce paramètre avec une langue cible qui ne prend pas en charge la formalité échouera, à moins que l’une des options prefer_… ne soit utilisée.
Par conséquent, pour être sûr qu’une traduction fonctionnera, au lieu d’écrire formality = "less" il faut écrire formality = "prefer_less" qui n’utilisera la formalité que si elle est disponible.
🔗 Conclusion
Dans ce billet, nous avons expliqué comment traduire un article de blog Hugo à l’aide de babeldown.
Bien que l’essentiel soit d’utiliser un appel à babeldown::deepl_translate_hugo(),
- il faut indiquer l’URL et la clé de l’API,
- on peut améliorer les résultats en utilisant les différents arguments de la fonction,
- nous recommandons d’associer la traduction à un flux de travail Git + GitHub (ou GitLab, gitea…).
babeldown a des fonctions pour traduire les chapitres de livres Quarto, n’importe quel fichier Markdown et n’importe quelle chaîne de caractères Markdown, avec des arguments et une utilisation recommandée similaires, alors explorez sa référence !
Nous serions ravis d’entendre parler de vos cas d’utilisation.
Mais il faut se référer à la documentation de tinkr pour voir ce qui pourrait changer dans le style de syntaxe Markdown. ↩︎
ajout de code pour gérer l’interface d’Hugo. “l’ensemble déconcertant d’emplacements de configuration possibles” et les deux formats possibles (YAML et TOML) est hors de portée de babeldown pour le moment. ↩︎
Catégories
Suggérer une modification
Ouvrir une pull request
