
Monday, September 10, 2018 From rOpenSci (https://ropensci.org/blog/2018/09/10/github-badges/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
A while ago we
onboarded an
exciting package, codemetar
by Carl Boettiger. codemetar is an R specific
information collector and parser for the CodeMeta
project. In particular, codemetar can
digest metadata about an R package in order to fill the terms
recognized by CodeMeta. This means
extracting information from DESCRIPTION but also from e.g. continuous
integration1 badges in the README! In this note, we’ll take advantage
of codemetar::extract_badges function to explore the diversity of
badges worn by the READMEs of CRAN packages.
🔗 Why codemetar::extract_badges(), and how
CodeMeta recognized terms include information we’ve been getting from badges:
“contIntegration”, URLs to continuous integration services such as Travis, Appveyor, Codecov;
“review”, information about review of the software if there was one.
codemetarrecognizes information from the peer-review badge we add to the README of onboarded packages thanks to work by Karthik Ram.
The list might get longer, so instead of using regular expressions on
the README text, we extract and memoize2 all badges at once to a
data.frame that we then query. The badges extraction is based on (in the
dev branch of codemetar):
conversion to XML using
commonmark(see my recent tech note) which works well for the Markdown badges e.g.[](https://travis-ci.org/ropensci/codemetar).extraction and parsing on the first HTML table there is if there’s any, which is necessary for badges in table, which we’ve been discussing for our guidelines.
Note that the CRAN version of codemetar already features
extract_badges, but with a badges table creation based on regular
expressions only (and a small encoding bug). Here is codemetar::extract_badges in action on the
README of the drake package:
library("magrittr")
codemetar::extract_badges("https://raw.githubusercontent.com/ropensci/drake/master/README.md") %>%
knitr::kable()
Quite handy for our metadata collection!
Read the source for extract_badges
here
and see how it’s used in this
script.
You can also compare codemetar’s
README
with its
codemeta.json
e.g. the lines for
“contIntegration”.
Now since, codemetar::extract_badges exports a nice data.frame for any
README with badges, and is exported, it’d be too bad not to use it to
gain insights from many, many READMEs!
🔗 Extract badges from CRAN packages
In this exploration we shall concentrate on CRAN packages that indicate
a GitHub repo link under the URL field of DESCRIPTION. By the way, if
you don’t indicate such links in DESCRIPTION of your package yet, you
can (and should) run
usethis::use_github_links.
🔗 Get links to GitHub repos from CRAN information
I reckon that I could have also used BugReports like Steven M Mortimer
did in his great analysis of CRAN downloads and GitHub
stars. I
am unsure of how one can get the link to and the content of the README
of packages that don’t Rbuildignore their README, such as
codemetar
(see under Material). The imperfect sample I collected will do for this
note.
Here’s how I got all the repo owners and names:
cran_db <- tools::CRAN_package_db()
# only packages that have a GitHub repo
github_cran <- dplyr::filter(cran_db[, c("Package", "URL")],
stringr::str_detect(URL, "github\\.com"))
# will need to keep only the URL to the repo
select_github_repo <- function(URL){
URLs <- stringr::str_split(URL, pattern = ",", simplify = TRUE)
github_repo <- URLs[stringr::str_detect(URLs, "github\\.com")][1]
github_repo <- stringr::str_remove(github_repo, "\\#.*$")
github_repo <- stringr::str_remove(github_repo, "\\#.*[ \\(.*\\)]")
github_repo <- stringr::str_remove(github_repo, "/$")
stringr::str_replace(github_repo,".*\\.com\\/", "")
}
github_cran <- dplyr::group_by(github_cran, Package)
github_cran <- dplyr::mutate(github_cran, github = select_github_repo(URL))
github_cran <- tidyr::separate(github_cran, github, "\\/",
into = c("owner", "repo"))
github_cran <- dplyr::ungroup(github_cran)
# Not very general
github_cran$repo[which(github_cran$Package == "webp")] <- "webp"
I needed a bit of string cleaning mostly to deal with the URLs of Jeroen Ooms’ packages, see e.g. this one. I guess I could have cleaned even more, but it was good enough for this exploration.
🔗 Get all badges
Then for each repo I queried the download URL of the preferred
README
via GitHub’s V3 API, using the gh
package. The preferred README is the one
GitHub displays on the repo landing page. I used
codemetar::extract_badges, of course. I rate-limited the basic
function using ratelimitr.
library("magrittr")
github_cran <- readr::read_csv("data/github_cran_links.csv")
.get_badges <- function(owner, repo){
message(paste(owner, repo, sep = "/"))
readme <- try(gh::gh("GET /repos/:owner/:repo/readme",
owner = owner, repo = repo),
silent = TRUE)
if(inherits(readme, "try-error")){
return(NULL)
}else{
badges <- codemetar::extract_badges(readme$download_url)
if(nrow(badges)>0){
badges$owner <- owner
badges$repo <- repo
}
return(badges)
}
}
.get_badges %>%
ratelimitr::limit_rate(ratelimitr::rate(1, 1)) -> get_badges
purrr::map2_df(github_cran$owner,
github_cran$repo,
get_badges) -> badges
🔗 Remove non badges from the sample
The way badges are recognized by codemetar::extract_badges is not
specific enough, it can include images formatted like badges that aren’t
badges but instead either local images or images whose credit is shown
as URL. To remove them from the sample, I used a strategy in two steps:
I first had a look at the most common domains. For the 17 most common of them, I accepted the images except for one, ropensci.org, included because the footer our packages get is formatted as a Markdown badge.
For the remaining images, a bit more than 200, I used
magickto obtain their width and height, and filtered actual badges based on their width/height ratio. Sometimes the link to the image wasn’t even valid, which was also a reason for exclusion, since it revealed the image was a local one.
# extract and parse URLs
badges %>%
dplyr::pull(image_link) %>%
purrr::map_df(urltools::url_parse) -> parsed_image_links
# count hits by domain
parsed_image_links %>%
dplyr::count(domain, sort = TRUE) -> domain_count
# these were manually inspected
# as legit badge providers
ok_domain <- domain_count$domain[1:17]
# keep the badges needing a check
tbd <- dplyr::filter(parsed_image_links,
! domain %in% ok_domain)
# get their size ratio
get_size <- function(url){
img <- try(magick::image_read(url),
silent = TRUE)
if(inherits(img, "try-error")){
tibble::tibble(error = TRUE,
image_link = url)
}else{
info <- magick::image_info(img)
info$error <- FALSE
info$image_link <- url
info
}
}
img_info <- purrr::map_df(urltools::url_compose(tbd),
get_size)
img_info <- dplyr::mutate(img_info, ratio = width/height)
# filter badges from images
img_info <- dplyr::filter(img_info,
ratio < 3|error)
# it'd have been wiser to use a row-wise workflow!
badges <- dplyr::filter(badges,
!image_link %in% img_info$image_link,
!image_link %in% stringr::str_remove(img_info$image_link,
"/$"),
!tolower(image_link) %in% img_info$image_link,
!tolower(image_link) %in% stringr::str_remove(img_info$image_link,
"/$"),
!stringr::str_detect(image_link,
"ropensci\\.org\\/public\\_images\\/"))
readr::write_csv(badges, "data/aaall_badges.csv")
Don’t judge me by my filenaming skills. I was maybe a bit too enthusiastic!
🔗 Analyze badges from CRAN packages
I wanted to answer several questions about the badges of CRAN packages, beyond being just happy to have been able to collect so many of them.
🔗 How many repos have at least one badge?
github_cran <- readr::read_csv("data/github_cran_links.csv")
# the same repo can have been used by several packages!
badges <- readr::read_csv("data/aaall_badges.csv")
badges <- dplyr::distinct(badges)
nobadges <- dplyr::anti_join(github_cran, badges,
by = c("owner", "repo"))
There are 1277 packages without any badge (or rather said, without any badge that we identified) out of a sample of 3541 packages. That means 64% have at least one badge. As a reminder, there are more than 13,000 packages on CRAN so we’re only looking at a subset.
🔗 Among the repos with badges, how many badges?
library("magrittr")
badges %>%
dplyr::count(repo, owner,
sort = TRUE) -> badges_count
badges_count %>%
dplyr::summarise(median = median(n))
## # A tibble: 1 x 1
## median
## <int>
## 1 4
library("ggplot2")
badges_count %>%
ggplot() +
geom_histogram(aes(n))+
hrbrthemes::theme_ipsum(base_size = 12,
axis_title_size = 12,
axis_text_size = 12) +
ggtitle("Number of badges per repo",
subtitle = "Among repos with at least one badge")
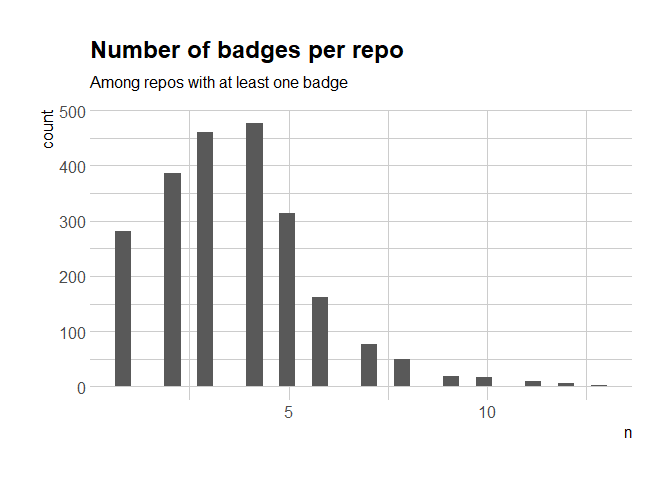
The median number of badges is 4, which corresponds to my gut feeling that the answer would be “a few”. I have a new question, what are the repos with the most badges?
most_badges <- dplyr::filter(badges_count,
n == max(n))
most_badges
## # A tibble: 2 x 3
## repo owner n
## <chr> <chr> <int>
## 1 gpuR cdeterman 13
## 2 psycho.R neuropsychology 13
You can browse them at https://github.com/cdeterman/gpuR, https://github.com/neuropsychology/psycho.R.
🔗 How many unique badges are there?
For counting types of badges, I’ll use the domain of image_link. This
is an approximation, since e.g. www.r-pkg.org offers several badges.
badges %>%
dplyr::pull(image_link) %>%
purrr::map_df(urltools::url_parse) -> parsed_image_links
parsed_image_links %>%
dplyr::pull(domain) %>%
unique() %>%
sort() -> unique_domains
length(unique_domains)
## [1] 50
Not that many after all, so I’ll print all of them! A special mention to https://github.com/ropensci/cchecksapi#badges maintained under our GitHub organization by Scott Chamberlain, to show the CRAN check status of your package!
Unique badge domains collapsed by glue::glue_collapse(unique_domains, sep = ", ", last = " and "): anaconda.org, api.codacy.com, api.travis-ci.org, app.wercker.com,
assets.bcdevexchange.org, awesome.re, badge.fury.io,
badges.frapsoft.com, badges.gitter.im, badges.herokuapp.com,
badges.ropensci.org, bestpractices.coreinfrastructure.org,
ci.appveyor.com, circleci.com, codeclimate.com, codecov.io,
coveralls.io, cranchecks.info, cranlogs.r-pkg.org, depsy.org,
dmlc.github.io, eddelbuettel.github.io, githubbadges.com,
githubbadges.herokuapp.com, gitlab.com, hits.dwyl.io, i.imgur.com,
img.shields.io, jhudatascience.org, joss.theoj.org, mybinder.org,
popmodels.cancercontrol.cancer.gov, pro-pulsar-193905.appspot.com,
raw.githubusercontent.com, readthedocs.org, saucelabs.com,
semaphoreci.com, travis-ci.com, travis-ci.org,
user-images.githubusercontent.com, usgs-r.github.io, www.nceas.ucsb.edu,
www.ohloh.net, www.openhub.net, www.paypal.com, www.r-pkg.org,
www.rdocumentation.org, www.repostatus.org, www.rpackages.io and
zenodo.org.
🔗 What are the most common badges?
Note that this doesn’t take into account the fact that one domain can appear several times in a single README (Travis status for different branches for instance).
parsed_image_links %>%
dplyr::count(domain, sort = TRUE) %>%
head(n = 10) %>%
knitr::kable()
| domain | n |
|---|---|
| travis-ci.org | 1880 |
| www.r-pkg.org | 1804 |
| cranlogs.r-pkg.org | 1286 |
| img.shields.io | 882 |
| ci.appveyor.com | 698 |
| codecov.io | 656 |
| www.repostatus.org | 240 |
| zenodo.org | 197 |
| coveralls.io | 157 |
| www.rdocumentation.org | 86 |
The most common badges are Travis-CI badges, and METACRAN badges from www.r-pkg.org and cranlogs.r-pkg.org. Now, “img.shields.io” is a service for badges of other things… which?
badges %>%
dplyr::filter(stringr::str_detect(image_link, "img\\.shields\\.io")) %>%
dplyr::count(text, sort = TRUE)
## # A tibble: 135 x 2
## text n
## <chr> <int>
## 1 Coverage Status 196
## 2 License 91
## 3 lifecycle 62
## 4 CoverageStatus 54
## 5 <NA> 38
## 6 packageversion 37
## 7 Last-changedate 32
## 8 Licence 28
## 9 minimal R version 28
## 10 Github Stars 19
## # ... with 125 more rows
Diverse things, in particular the Tidyverse lifecycle badges. After some discussion, we at rOpenSci have adopted the repostatus.org status badges in our guidelines… but are actually open to repos using both types of badges since their nomenclature can complement each other!
🔗 Conclusion
In this tech note I presented and used one of codemetar’s tools for R
package metadata munging, extract_badges. I extracted and analyzed
badges information from the READMEs of all CRAN packages that indicate a
GitHub repo in the URL field of DESCRIPTION. README badges are a way to
show development status, test results, code coverage, peer-review merit,
etc.; but can also be used as a machine-readable source of information
about these same things.
Explore more of codemetar in its GitHub
repo, and check out the
CodeMeta project itself. Read our
guidelines for package development and maintenance in this
gitbook. And have fun adding
pretty badges to your own package repos upping your package
development & maintenance game!
If you’re new to continuous integration I’d recommend reading this great post of Julia Silge’s, and this chapter of our guide for package development. ↩︎
Memoizing a function means that when called again during the same R session with the same parameters, a cached answer is used. See the vignette of the
memoisepackage. ↩︎
Filed under
Suggest an edit
Open a pull request

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}