
Thursday, July 16, 2020 From rOpenSci (https://ropensci.org/blog/2020/07/16/cran-checks-docs-notifications/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
In October last year we wrote about the CRAN Checks API (https://cranchecks.info). Since then there have been four new major items introduced: documentation, notifications, search, and a new version of the cchecks R package. First, an introduction to the API for those not familiar.
🔗 CRAN Checks API
The CRANS checks API was born because whilst being crucial to a package’s fate on CRAN, CRAN checks results were not available in a machine readable format, contrary to checks from continuous integration services. Indeed, CRAN checks results are only distributed as HTML pages. Therefore CRAN checks API’s goal is to provide data from CRAN checks in a format that’s easier to work with from code.
CRAN checks are presented for packages in html meant for browser interaction, in a combination of tables, lists and text. On our server we scrape checks data for each package, and manipulate the data into a format that can be easily stored and searched, and then made machine readable.
The main thing this API is used for is badges like the one below that indicate status of the CRAN checks for a package. Many package maintainers have these in the README of their code repository.

🔗 Documentation
APIs are not very useful without good documentation.
Maëlle re-organized existing docs into a website made with Hugo: https://docs.cranchecks.info/
The documentation includes explanation of all the API routes, and includes examples in Shell/command line and for use in R.
There’s also detailed explanation of notifications, see below.
For those interested in details about the Hugo website, here are a few. You can find the website source on GitHub.
The theme is an edited version of bep’s docuapi theme in order to allow for more flexibility of code tabs. Note that bep is Hugo maintainer, so that was a good theme to build upon. The docuapi theme uses Go modules. The way languages are divided into tabs relies on using data attributes that a JavaScript script can then access.
The website source includes some knitr hooks to deal with chunks of various languages. It might be a bit overcomplicated and could be simplified in the future, but it works for now.
Using GitHub Actions, an R script is run every week to update the documentation.
Apart from data attributes, another cool HTML thing we learnt about for this website is the Markdown extension for creating a description list.
parameter
: its definition
is rendered to
- parameter
- its definition
Regarding the website styling, we didn’t tweak it much. We added an rOpenSci logo, and use a dark theme for code highlighting (a tweak version of the Chroma fruity style, to add some contrast).
🔗 cchecks R package
The cchecks package has been around for a while, but has received a lot of work recently, and is up to date with the current CRAN checks API. It is not on CRAN right now. To get started see the docs for the package at https://docs.ropensci.org/cchecks, as well as the API docs at https://docs.cranchecks.info/. You can install it like:
remotes::install_github("ropenscilabs/cchecks")
Below we talk about using cchecks for notifications and searching check results, so we’ll give a brief example of some of the other functions here.
In our October 2019 blog post we discussed accessing “historical” data, that is, data older than 30 days from the present day. Data is stored in an Amazon S3 bucket, with a separate gzipped JSON file for each day. In October ‘19 we had the API route, but now you can access the data easily within R:
library(cchecks)
cch_history(date = "2020-04-01")
The cch_history() function calls our API, which returns a link to the file in the S3 bucket. We then download the file and then jsonlite reads in the JSON data to a data.frame. Using this function you can quickly get historical checks data if you need to do some archeological work.
To get checks data for specific packages up to 30 days old, we can use the cch_pkgs_history() function:
cch_pkgs_history("MASS")
cch_pkgs_history(c("crul", "leaflet", "MASS"))
So when you need historical CRAN checks data, you’ll use either cch_pkgs_history() (data for specific packages, up to 30 days in the past) or cch_history() (data for all packages, one day by function call, back to 2018-12-18), or a combination of both, depending on your needs.
The resulting data is in both cases a data.frame so you can use your favorite R data munging tools.
🔗 Notifications
Good technical solutions are often born from scratching one’s own itch. The first author has many packages on CRAN and would like to avoid getting emails from the CRAN maintainers with a deadline to fix a problem. If I could only know about a problem with a CRAN check and fix it quickly, we’re all better off as users get fixes quickly, and CRAN maintainers email burden is that much less.
We’re announcing here the availability of CRAN checks notifications. These notificaitons are emails; there could be other forms (e.g., Twitter, etc.), but emails probably meet most people’s needs. To get started see the docs at https://docs.cranchecks.info/#notifications.
Notifications work via a rule that you set. A rule is made up of one or more of four categories:
- status: match against check status. one of: ok, note, warn, error, or fail
- time: days in a row the match occurs. an integer. can only go 30 days back (history cleaned up after 30 days)
- platforms: platform the status occurs on, including negation (e.g., “-solaris”). options: solaris, osx, linux, windows, devel, release, patched, oldrel
- regex: a regex to match against the text of an error in
check_details.output
A user can set as many rules as they like. A package can have more than one rule. Users can delete only their own rules (as one would expect). Rules are used indefinitely, until deleted by the user.
Once a rule is triggered an email is sent to the user. We won’t send the same email for 5 days. After 5 days has past, if the rule is matched, we’ll send the same email; and repeat.
Feel free to ignore these emails, or act them as you see fit.
The email is structured as follows:
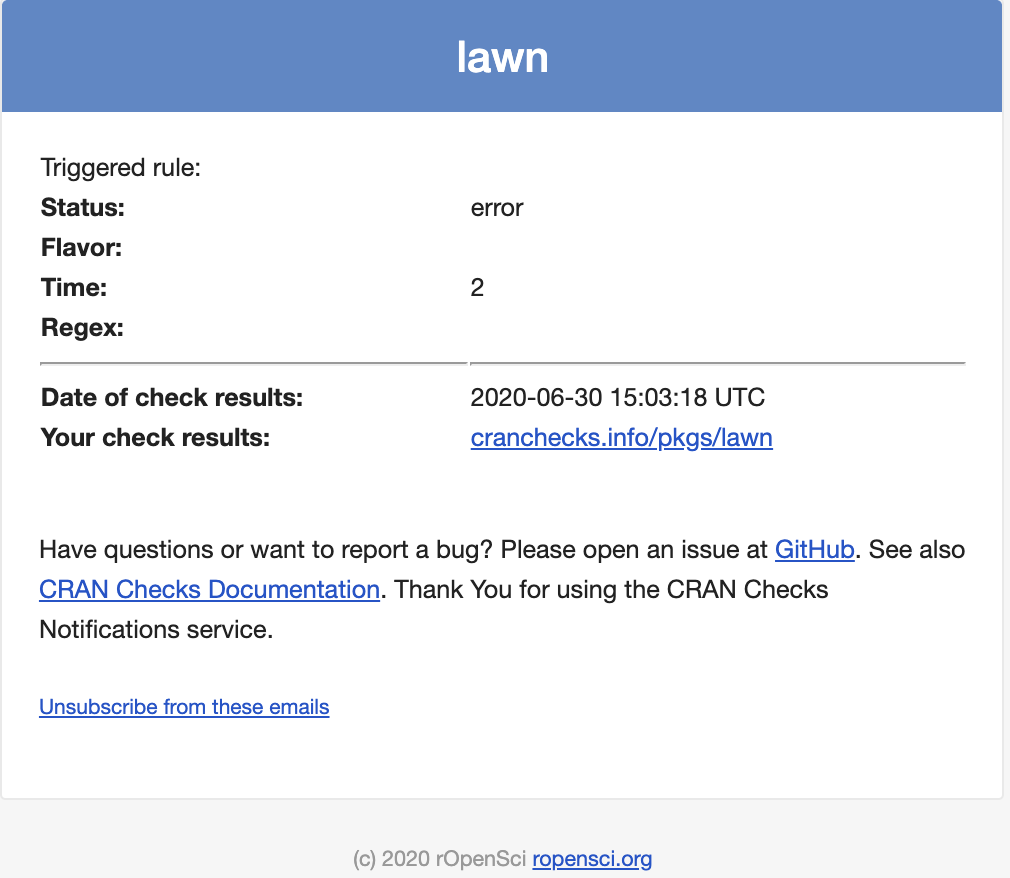
- Triggered rule: with a list of each of the four categories and their values.
- Date of the check result (matches closely the date on the CRAN check results that CRAN maintainers created)
- Your check results: link to the CRAN checks API JSON output for your package
- The rest is information, report bugs, ask for help, etc. Note the “Unsubscribe” link doesn’t actually work yet!
🔗 Managing notifications
There is no web interface to notifications at this time. The only official interface is the cchecks R package - you are welcome to interact with the API itself via curl or any other tool.
First, you’ll need to register for a token (aka key). Using cchn_register(), you run the function with or without an email address. If no email address is given we look for an email address in various places, and ask you which one you’d like to use, or you can supply one at the prompt.
cchn_register()
Running cchn_register() caches the token in a file locally on your computer.
After registering, you can manage rules for your packages. There’s two ways to manage rules: a) across packages, or b) in a single package context.
Functions prefixed with cchn_pkg_ operate within a package directory. That is, your current working directory is an R package, and is the package for which you want to handle CRAN checks notifications. These functions make sure that you are inside of an R package, and use the email address and package name based on the directory you’re in.
Functions prefixed with just cchn_ do not operate within a package. These functions do not guess package name at all, but require the user to supply a package name (for those functions that require a package name); and instead of guessing an email address from your package, we guess email from the cached email/token file.
If you don’t use the package specific functions, you can add a rule like:
cchn_rule_add(package = "foobar", status = "warn", platform = 2)
Using package specific functions, you can add a rule like:
cchn_pkg_rule_add(status = "warn", platform = 2)
See cchn_rules_add() for adding many rules at once.
What the first author does currently is a rule for each of his packages checking for a status of ERROR for at least 2 days. This would look like the below for an example set of three packages.
pkgs <- c("charlatan", "randgeo", "rgbif")
rules <- lapply(pkgs, function(z) list(package = z, status = "error", time = 2))
cchn_rules_add(rules, "[email protected]")
You could take this approach as well for your packages. We are thinking about ways to build in some sensible default rules, as well as making it easier to work across all of your packages by looking them up for you by your maintainer email.
🔗 Search
A benefit of having a proper database (aka SQL) of anything is that you can search it. We did not have search until May 2020, so it’s relatively new. Search allows users to do full-text search the check_details field of the 30-day historical data across all packages. There’s a few parameters users can toggle, including one_each (boolean) to only return a single result per matching package (rather than results for all days matching). The equivalent function in the R package is cchecks::cch_pkgs_search().
Here, we search for the term memory:
cchecks::cch_pkgs_search(q = "memory")
#> $error
#> NULL
#>
#> $count
#> [1] 1299
#>
#> $returned
#> [1] 30
#>
#> $data
#> # A tibble: 30 x 5
#> package date_updated summary$any $ok $note $warn $error $fail checks
#> <chr> <chr> <lgl> <int> <int> <int> <int> <int> <list>
#> 1 cluste… 2020-08-08T… TRUE 0 9 0 2 1 <df[,…
#> 2 cluste… 2020-08-09T… TRUE 0 9 0 2 1 <df[,…
#> 3 cluste… 2020-08-10T… TRUE 0 9 0 2 1 <df[,…
#> 4 cluste… 2020-08-11T… TRUE 0 9 0 2 1 <df[,…
#> 5 cluste… 2020-08-12T… TRUE 0 10 0 2 0 <df[,…
#> 6 cluste… 2020-08-13T… TRUE 0 10 0 2 0 <df[,…
#> 7 cluste… 2020-08-24T… TRUE 0 10 0 2 0 <df[,…
#> 8 cluste… 2020-08-25T… TRUE 0 10 0 2 0 <df[,…
#> 9 allan 2020-08-08T… TRUE 0 9 0 3 0 <df[,…
#> 10 allan 2020-08-09T… TRUE 0 9 0 3 0 <df[,…
#> # … with 20 more rows, and 2 more variables: check_details$details <list>,
#> # $additional_issues <list>
The result is a list with number of results found, returned, and a data.frame of matches.
If you want to return only one result for package, use the one_each parameter:
cchecks::cch_pkgs_search(q = "memory", one_each = TRUE)
🔗 Wrap up
Please try out the various items discussed above, and give us feedback. Whether it’s about the documentation, the API itself, the notifications service, or the cchecks package - it’s all useful!
We’re particualarly interested in your feedback on the email notifications service. It’s still early days for the service, so we’re very keen to get all rough edges smoothed out to make for a good user experience.
Filed under
Suggest an edit
Open a pull request
