
Tuesday, August 25, 2020 From rOpenSci (https://ropensci.org/blog/2020/08/25/scientific-name-parsing/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
I’m starting to tackle a few hard packages (spplit and spenv) having to do with integrating disparate data sources. I’ll talk here about spplit. I haven’t worked on spplit in a few years; I thought I’d make another attempt with “fresh” eyes.
There are many use cases I can imagine for spplit; I’ll highlight a few. First, one may want to find literature that mentions particular scientific names (find all the journal articles that include the name Ursus americanus (American black bear)). Second, one could extract scientific names from scientific literature to examine the different formats of scientific names used in different journals (e.g., Homo sapiens vs. Homo sapiens Linnaeus vs. Homo sapiens Linnaeus, 1758). Last, you could extract the scientific names from your own manuscript before submission to check that all scientific names are properly formatted and match your preferred taxonomic reference.
In the process of re-visiting spplit, I sketched out a workflow that at least I think makes sense:
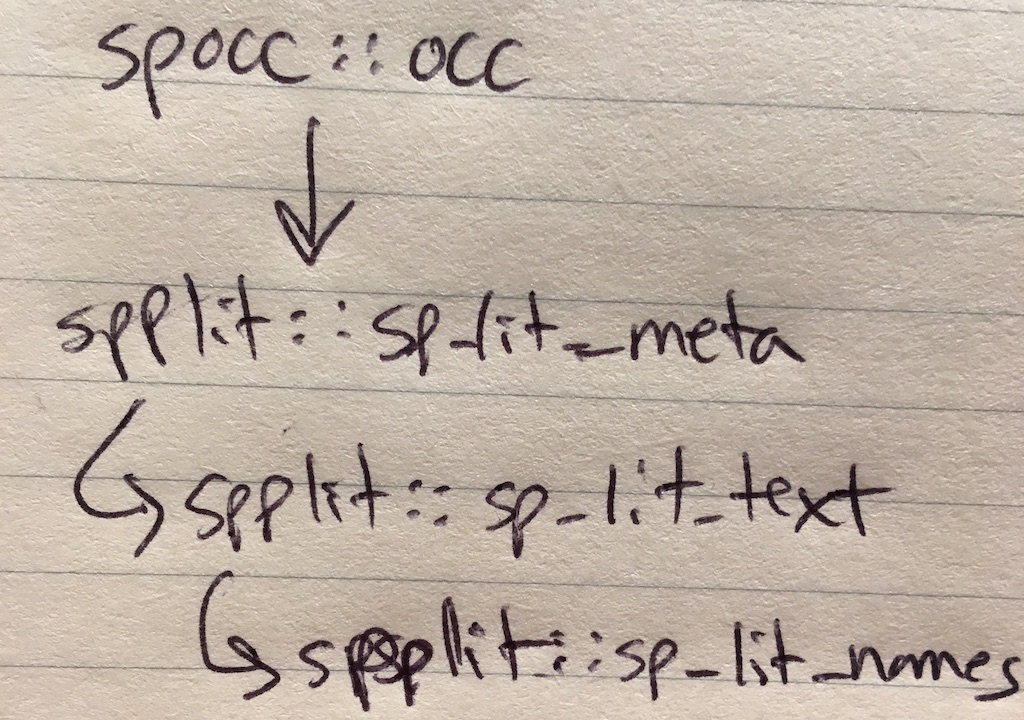
That is, one would gather species occurrence data with spocc::occ(), then use spplit::sp_lit_meta() to search the literature for the scientific names in the occurrence data (gathering literature metadata only), then use spplit::sp_lit_text() to gather the full text of the journal article (if available). With the full text of journal articles one may want to proceed to text mining, and in addition or instead, one may want to extract the scientific names from the articles gathered by spplit::sp_lit_text() in a function we’ll call spplit::sp_lit_names().
The literature bits can be done using fulltext and friends, but there weren’t any existing R tools that I knew of for the scientific name extraction part. However, I knew about great tooling written in the Go programming language by Dmitry Mozzherin.
Dmitry created the tool gnfinder to pull scientific names out of text, and the tool gnparser to parse scientific names into their component pieces. The work put into these two tools would be difficult to re-create in R (and I’ve definitely tried) - making them ideal for using in R as is.
🔗 Go and R
Unfortunately, despite some experiments, there isn’t a solution that I know of for using Go packages within R packages that would work on CRAN. If you know of one that works on CRAN let me know.
We can of course “shell out” to Go, which is what I’ve done with namext and rgnparser. Instead of using base system() I use the sys package for a bit nicer interface for doing system calls.
One nice thing about interfacing with Go is that Go makes it easy to make binaries for major computing platforms. So even though we’ll make system calls from R, at least we’re likely to not exclude users due to a binary not being available for their platform. I believe, correct me if I’m wrong, that you don’t even need to install Go to run a Go binary.
🔗 namext
The first step in spplit::sp_lit_names() would be to extract scientific names from an article.
Installation instructions can be found at the gnfinder repo. Download the latest release for your platform then move it to where it can be executed, e.g., sudo mv path_to/gnfinder /usr/local/bin/.
Once we have the plain text of an article (e.g., text extracted from a pdf or xml format) then we can use namext. There’s only one function in namext at the moment: name_extract().
First, install namext
remotes::install_github("ropenscilabs/namext")
Right now name_extract() only accepts a path to a file, which can be a pdf, in which case it will extract the text.
We’ll use the pdf from this article: https://doi.org/10.3897/BDJ.8.e54333
library(namext)
x <- "BDJ_article_54333.pdf"
out <- name_extract(x)
out
#> $metadata
#> # A tibble: 1 x 9
#> date gnfinderVersion withBayes tokensAround language detectLanguage
#> <chr> <chr> <lgl> <int> <chr> <lgl>
#> 1 2020… v0.11.1-2-g551… TRUE 0 eng FALSE
#> # … with 3 more variables: totalWords <int>, totalCandidates <int>,
#> # totalNames <int>
#>
#> $names
#> # A tibble: 713 x 8
#> cardinality verbatim name odds start end annotationNomen… annotation
#> <int> <chr> <chr> <dbl> <int> <int> <chr> <chr>
#> 1 1 Lepidopte… Lepid… 8.95e 3 2504 2516 NO_ANNOT ""
#> 2 2 Memecylon… Memec… 6.42e11 5790 5811 NO_ANNOT ""
#> 3 2 Syzygium … Syzyg… 9.09e10 5812 5827 NO_ANNOT ""
#> 4 2 Actinodap… Actin… 7.36e12 5832 5855 NO_ANNOT ""
#> 5 2 Carallia … Caral… 3.64e11 5929 5950 NO_ANNOT ""
#> 6 2 Glochidio… Gloch… 1.25e11 5951 5975 NO_ANNOT ""
#> 7 2 Olea dioi… Olea … 3.27e10 5976 5988 NO_ANNOT ""
#> 8 2 Garcinia … Garci… 4.87e10 5989 6004 NO_ANNOT ""
#> 9 2 Carissa c… Caris… 8.07e 8 6009 6025 NO_ANNOT ""
#> 10 2 Acacia au… Acaci… 7.39e 5 10214 10235 NO_ANNOT ""
#> # … with 703 more rows
The function found 317 unique scientific names.
🔗 rgnparser
After extracting scientific names from an article, or if you already have scientific names, you may want to parse the scientific names for any number of reasons: to cleave off authors from scientific names, or pull out just the epithets of each name, or extract just the years from the authors of each name.
Installation instructions can be found at the gnparser repo. Download the latest release for your platform then move it to where it can be executed, e.g., sudo mv path_to/gnparser /usr/local/bin/.
First, install rgnparser
remotes::install_github("ropensci/rgnparser")
The rgnparser package has a number of functions for different use cases, but we’ll focus on gn_parse_tidy().
Using a brief example to demonstrate the output:
library(rgnparser)
x <- c("Quadrella steyermarkii (Standl.) Iltis & Cornejo",
"Parus major Linnaeus, 1788", "Helianthus annuus var. texanus")
df <- gn_parse_tidy(x)
df
#> # A tibble: 3 x 9
#> id verbatim cardinality canonicalfull canonicalsimple canonicalstem
#> <chr> <chr> <dbl> <chr> <chr> <chr>
#> 1 e571… Heliant… 3 Helianthus a… Helianthus ann… Helianthus a…
#> 2 fbd1… Quadrel… 2 Quadrella st… Quadrella stey… Quadrella st…
#> 3 e4e1… Parus m… 2 Parus major Parus major Parus maior
#> # … with 3 more variables: authorship <chr>, year <dbl>, quality <dbl>
gnparser breaks down the names for us, so we can get just the scientific name without year/authors, or just authors, just years, etc.
df$canonicalsimple
#> [1] "Helianthus annuus texanus" "Quadrella steyermarkii"
#> [3] "Parus major"
df$authorship
#> [1] NA "(Standl.) Iltis & Cornejo"
#> [3] "Linnaeus 1788"
df$year
#> [1] NA NA 1788
Now that we’ve seen what gnparser can do on a small example, let’s use the output from the above text extraction step with namext:
gn_parse_tidy(unique(out$names$name))
#> # A tibble: 317 x 9
#> id verbatim cardinality canonicalfull canonicalsimple canonicalstem
#> <chr> <chr> <dbl> <chr> <chr> <chr>
#> 1 ac61… Lepidop… 1 Lepidoptera Lepidoptera Lepidoptera
#> 2 832b… Memecyl… 2 Memecylon um… Memecylon umbe… Memecylon um…
#> 3 5041… Actinod… 2 Actinodaphne… Actinodaphne l… Actinodaphne…
#> 4 9eb5… Syzygiu… 2 Syzygium cum… Syzygium cumini Syzygium cum…
#> 5 022e… Caralli… 2 Carallia int… Carallia integ… Carallia int…
#> 6 3c4f… Glochid… 2 Glochidion l… Glochidion lan… Glochidion l…
#> 7 f902… Olea di… 2 Olea dioica Olea dioica Olea dioic
#> 8 38bb… Garcini… 2 Garcinia ind… Garcinia indica Garcinia ind…
#> 9 182a… Carissa… 2 Carissa cara… Carissa carand… Carissa cara…
#> 10 d682… Lycaeni… 1 Lycaenidae Lycaenidae Lycaenidae
#> # … with 307 more rows, and 3 more variables: authorship <lgl>, year <lgl>,
#> # quality <dbl>
🔗 Conclusion
Would love any feedback from namext and rgnparser, both with respect to the packages themselves, and any trouble with installing the Go tooling.
Filed under
Suggest an edit
Open a pull request
